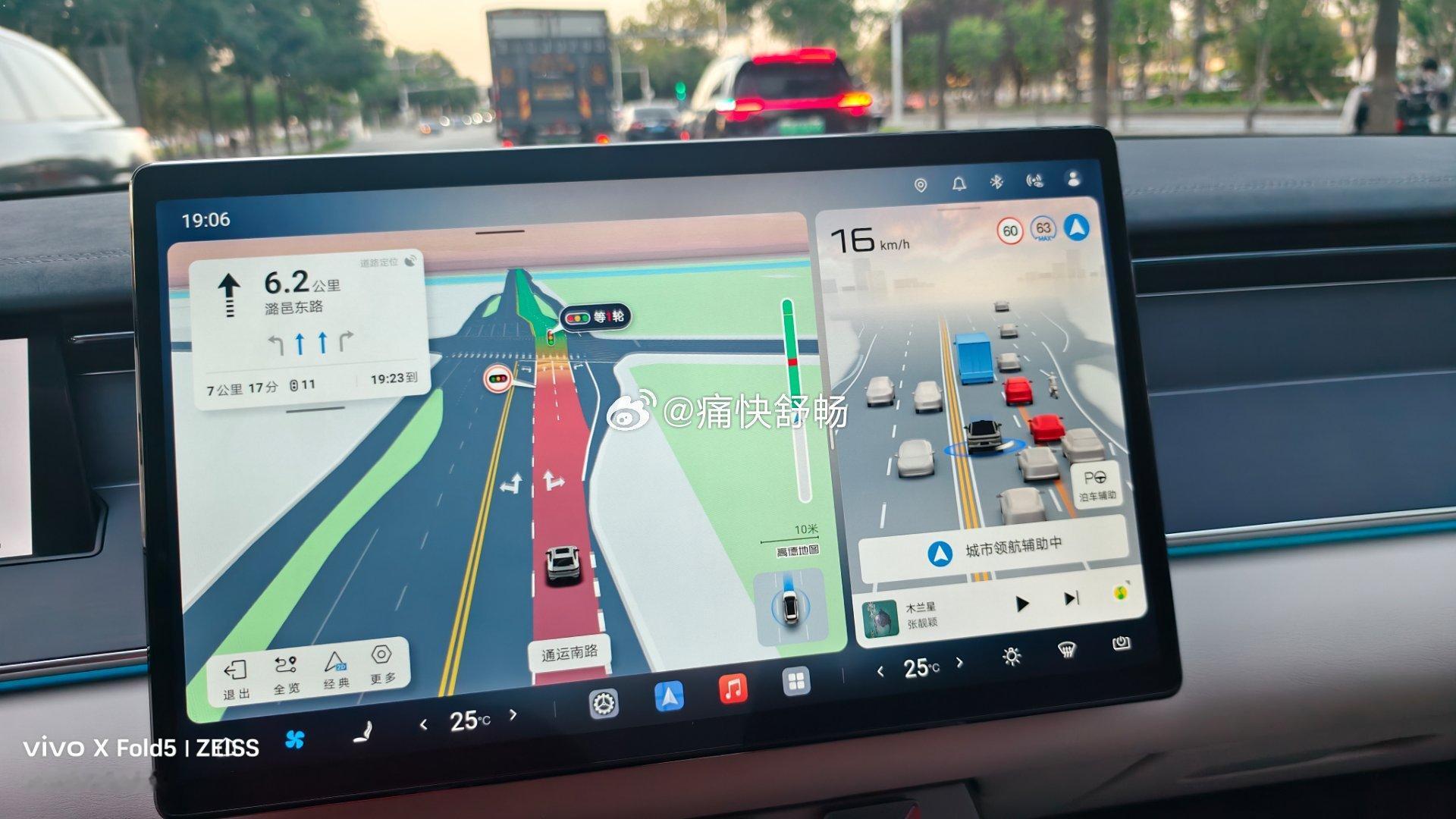
英伟达搞了个大模型,L4自动驾驶有戏了? 今天刷到英伟达发布Alpamayo 2 Super的消息,320亿参数,定位是开放推理VLA模型,专门给L4级自动驾驶用的。说实话第一反应是:又一个大模型来了,但这次好像不太一样。 先说说VLA是啥,用大白话讲。 传统的自动驾驶基本是"看一步走一步"——摄像头看到什么,模型判断一下,然后告诉车该怎么动。VLA的思路是把视觉、语言、动作三件事揉到一起,让车不只是"看见",而是能"理解"。打个比方,以前的自动驾驶像条件反射,VLA想做的更像是"带脑子开车"。比如前面有个施工工人在挥手,传统模型可能识别不了这是啥意思,VLA理论上能理解"这个人在指挥交通,我应该绕行"。 我觉得这事最值得关注的不是模型本身,而是"开放"这两个字。 英伟达这次把模型开源了,这意味着中小团队、高校、甚至个人开发者都能拿到这个级别的能力去做研究和落地。以前L4自动驾驶基本是Waymo、百度Apollo这种巨头的游戏,门槛高得离谱。现在英伟达把底座能力开放出来,相当于给大家发了一张入场券,能不能跑出成绩各凭本事。这对整个行业来说绝对是好事,竞争越充分,技术迭代越快。 但我得泼一盆冷水:从模型到真上路,中间隔着十万八千里。 320亿参数听起来很唬人,但自动驾驶的核心难题从来不是模型够不够大,而是长尾场景能不能处理好。什么叫长尾?就是那些你训练数据里几乎没见过的奇葩路况——逆行的外卖小哥、突然滚到路中间的轮胎、暴雨天看不清的车道线。这些场景不是靠堆参数就能解决的,需要海量的真实路测数据去喂,需要时间去打磨。特斯拉搞了这么多年FSD,到现在还在L2+徘徊,你就知道这事有多难。 再一个让我有点纠结的点:开源虽好,但落地靠生态。 英伟达的硬件生态确实强,从训练到推理的芯片都有,但自动驾驶不只是一个模型的事。你还需要传感器方案、高精地图(或者无图方案)、车规级硬件、安全冗余……每一环都是硬骨头。一个开源模型能加速其中一环,但指望它直接把L4拉到可商用的程度,我觉得还是想多了。 说到底我的看法是: 英伟达这步棋走得聪明,用开放生态抢占自动驾驶的"水电煤"位置。对行业来说是利好,技术门槛在降低,创新空间在变大。但对我们普通消费者来说,L4真正走进日常生活,保守估计还得再等个三五年。别被参数冲昏头,也别因为距离远就觉得无所谓——技术的种子已经种下了,就看什么时候开花。【来自懂车帝车友圈】