[CL]《Embarrassingly Simple Self-Distillation Improves Code Generation》R Zhang, R H Bai, H Zheng, N Jaitly… [Apple] (2026)
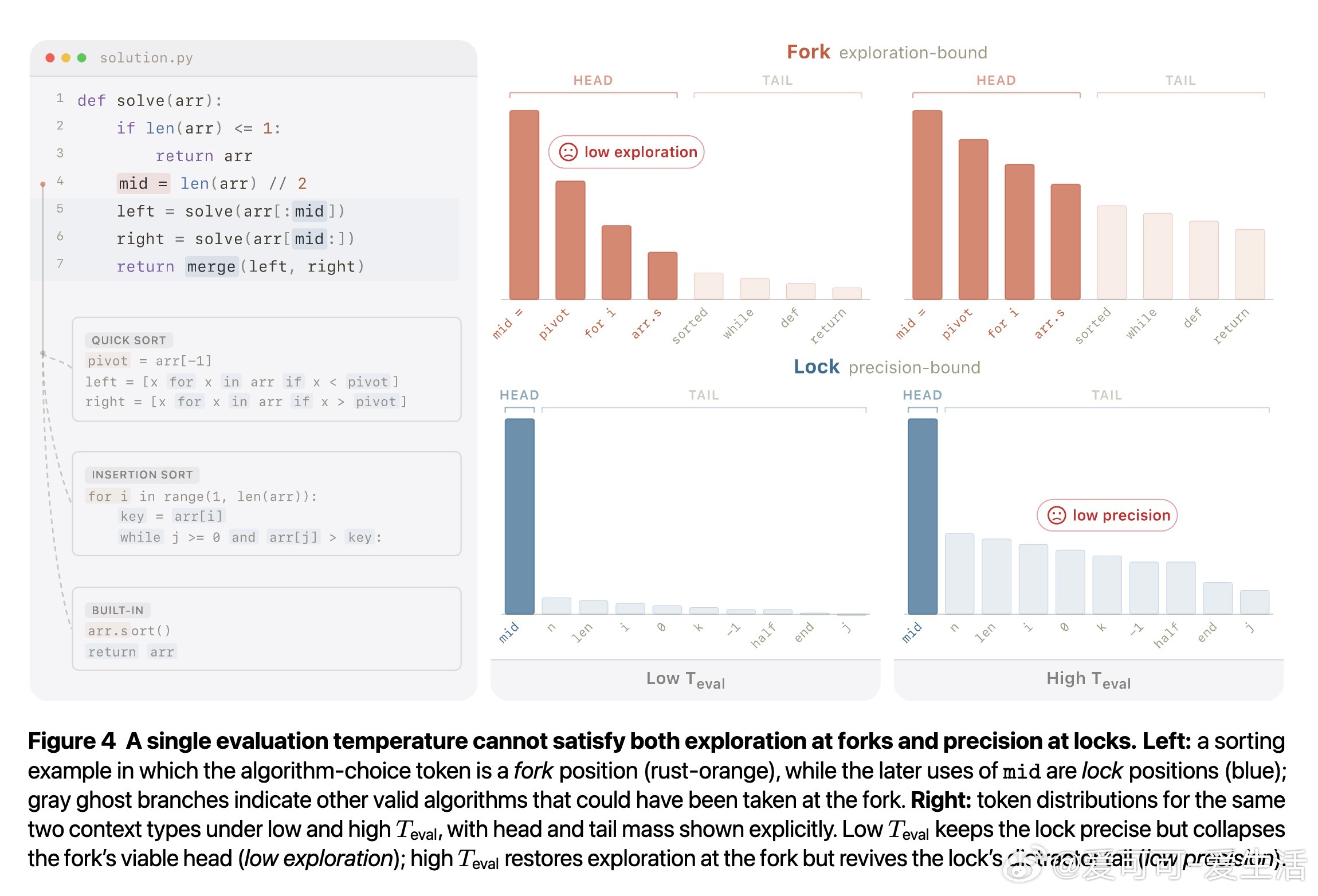
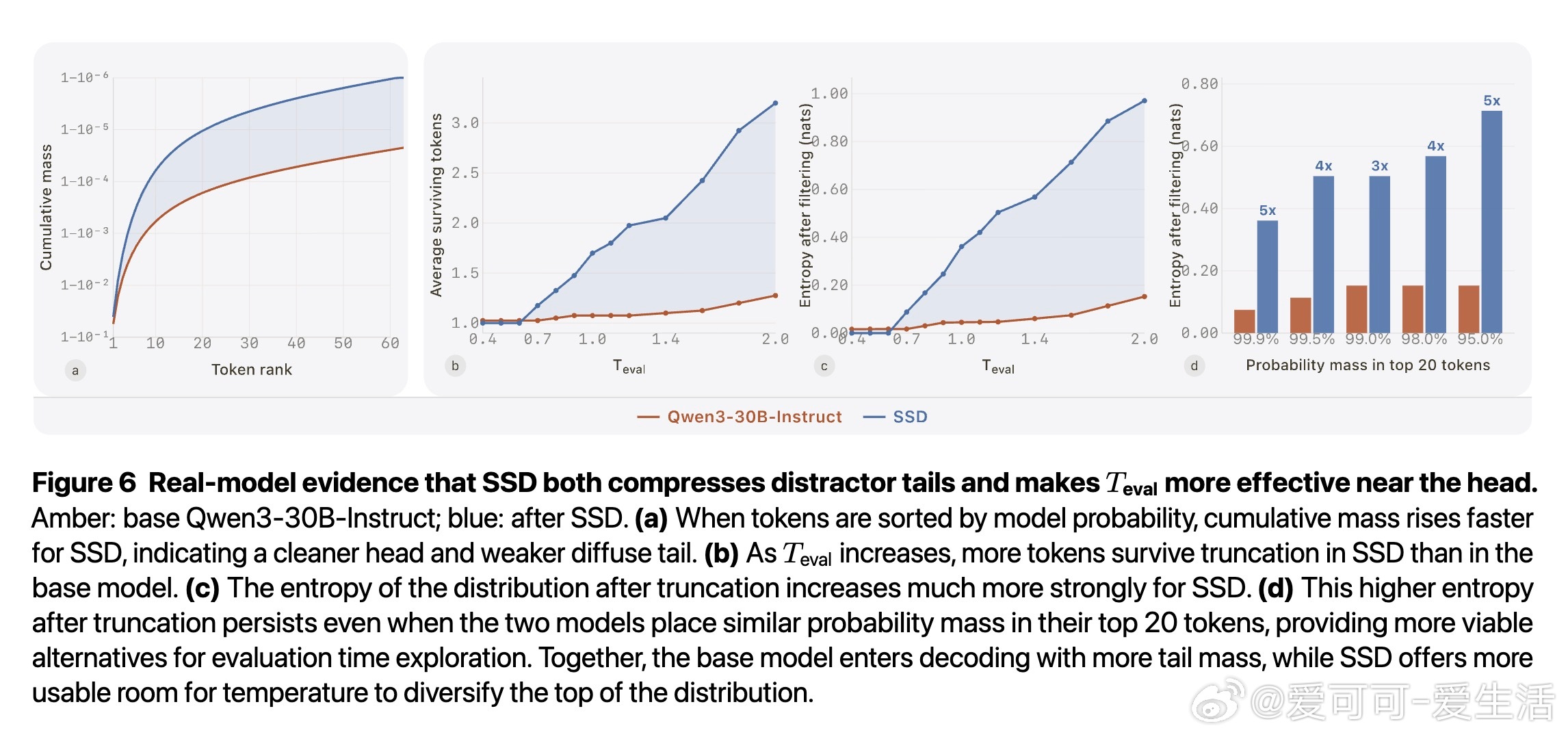
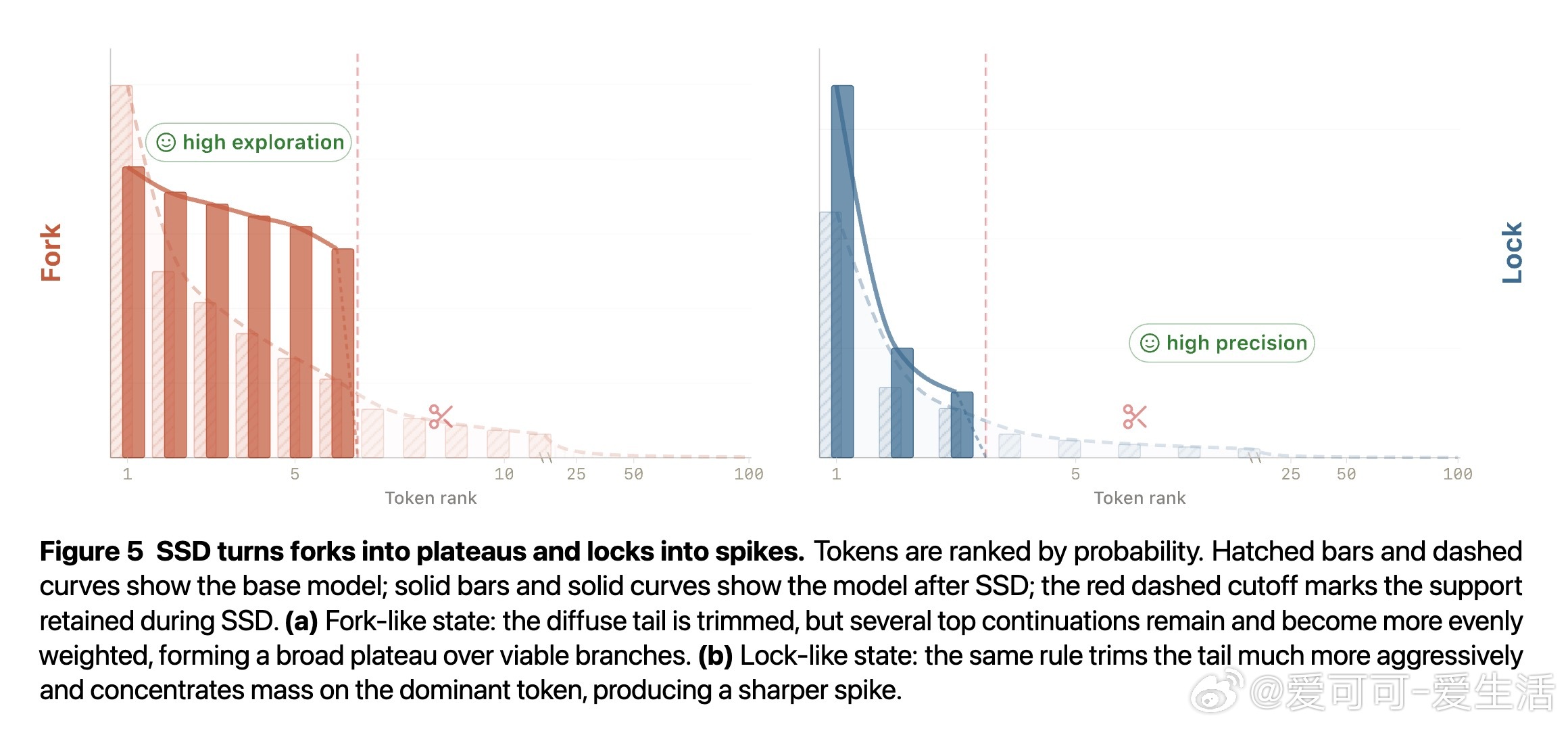
代码生成中,LLM 面临一个隐秘的结构性矛盾:序列中某些位置需要精确锁定唯一正确词元("锁"),另一些位置则需要在多条可行路径间自由探索("叉")。全局解码温度无法同时满足两者——降温保住了锁,却扼杀了叉的多样性;升温放开了叉,却让锁的干扰尾巴死灰复燃。现有方法或依赖更强的教师模型,或需要执行反馈验证,均绕开而非解决这一矛盾。
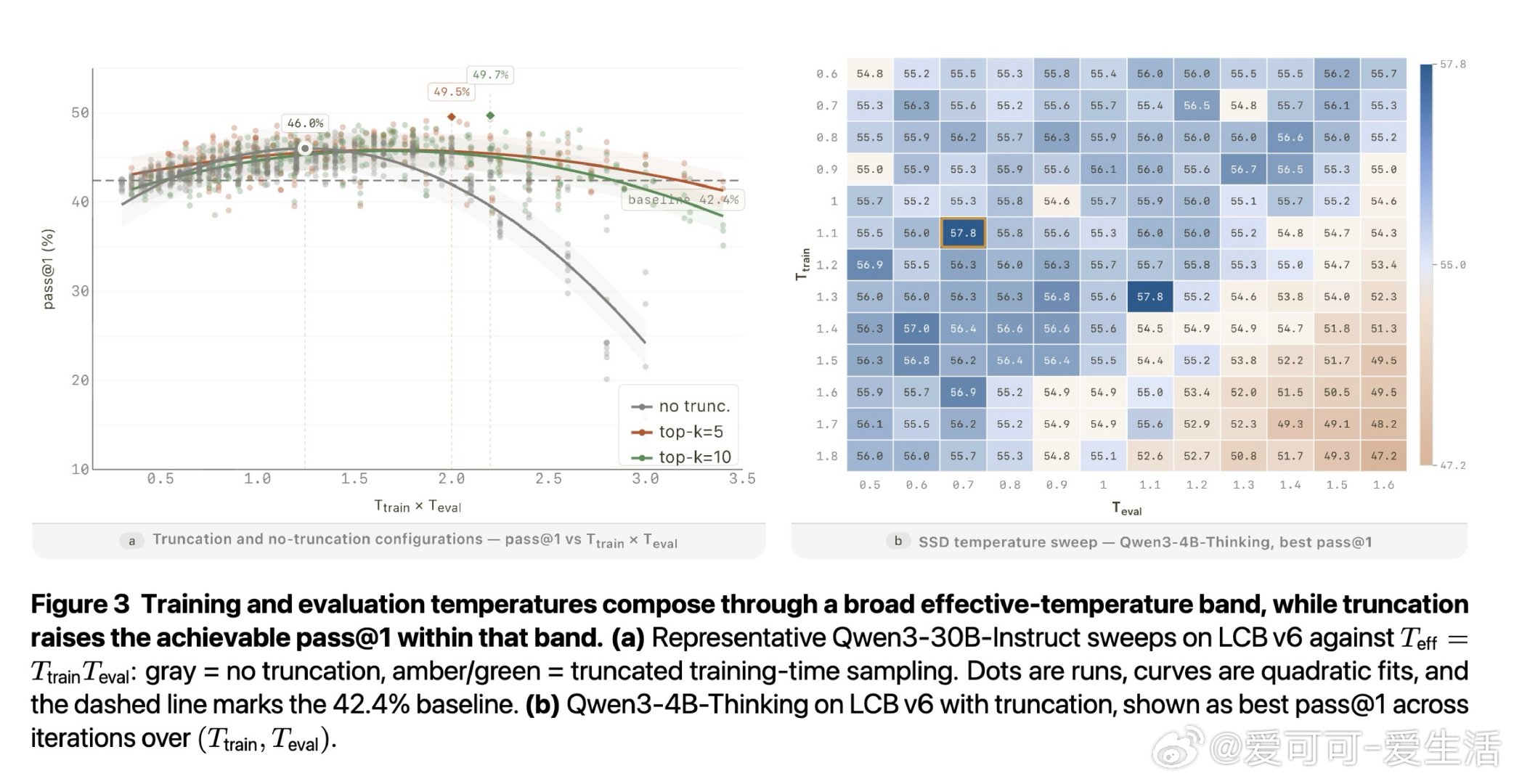
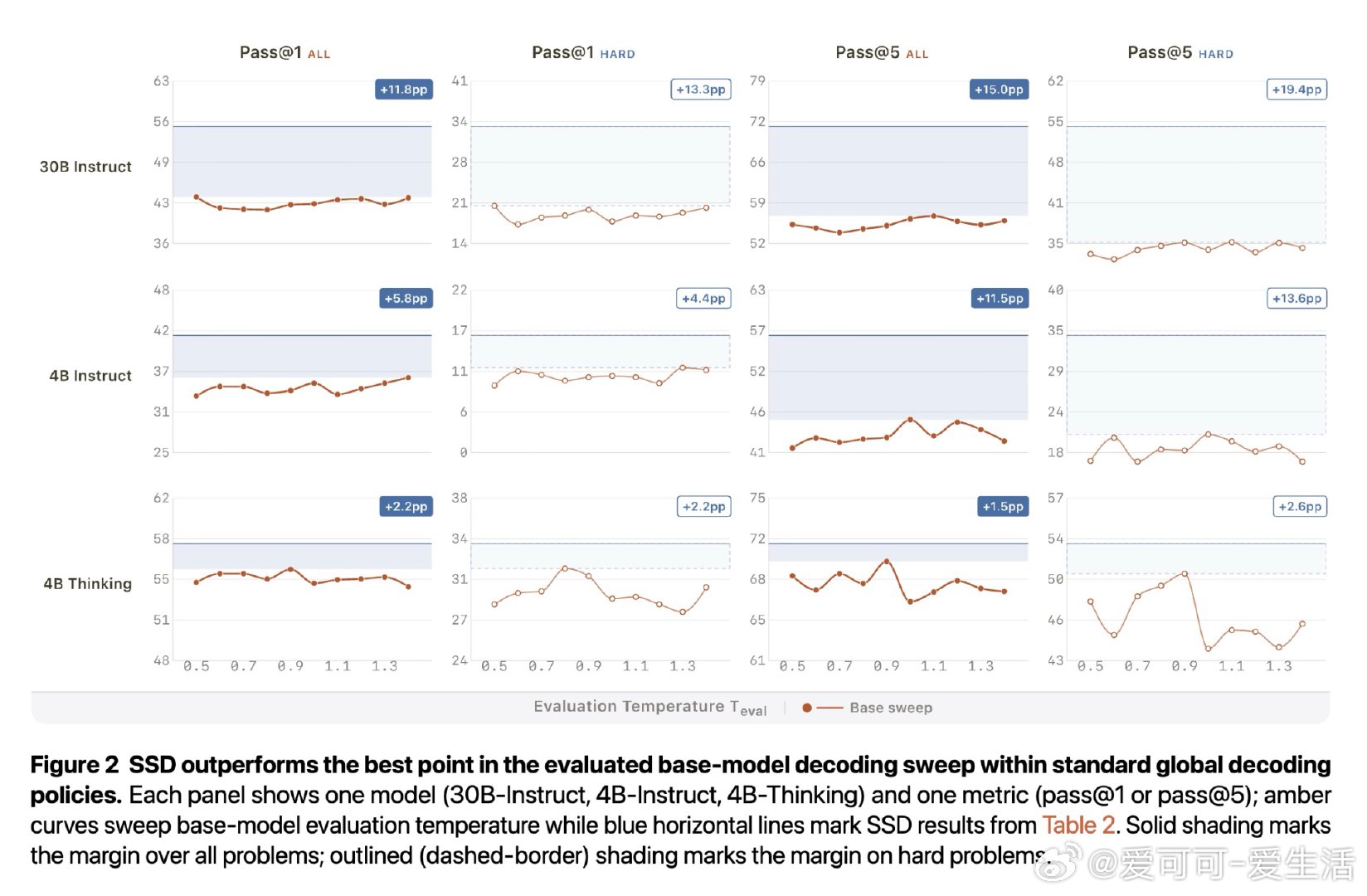
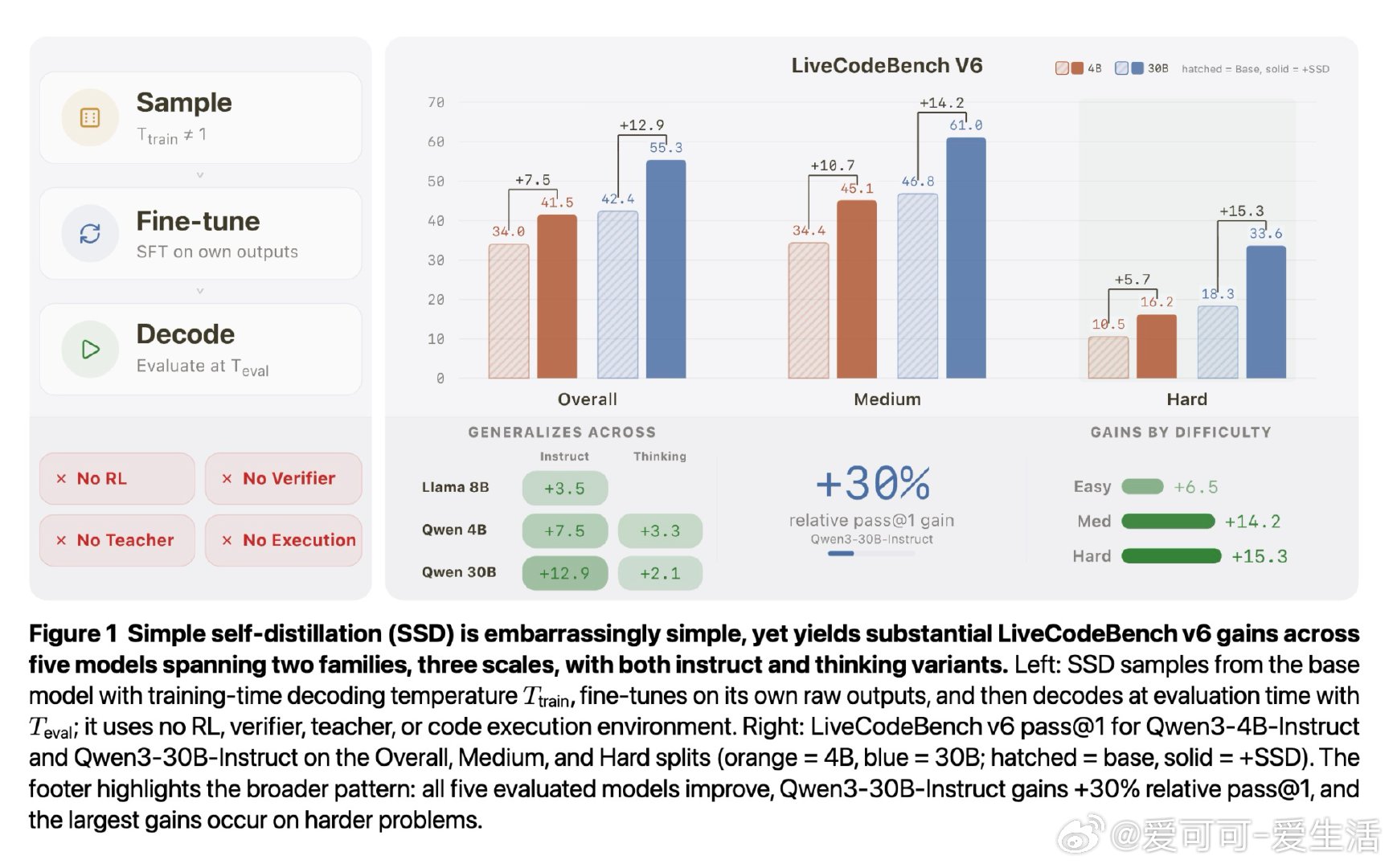
本文的核心洞见是:把"用什么数据训练"重新看作"用什么温度和截断配置采样自身输出"的问题。以高于默认温度采样、截断低概率尾部,再用标准监督微调训练回模型自身。这一操作迫使模型在"锁"位置聚拢概率质量、压制干扰尾,在"叉"位置则因保留多个可行词元而维持探索空间——两种效果由同一训练目标在不同支撑集几何上自适应产生,无需任何正确性标签。
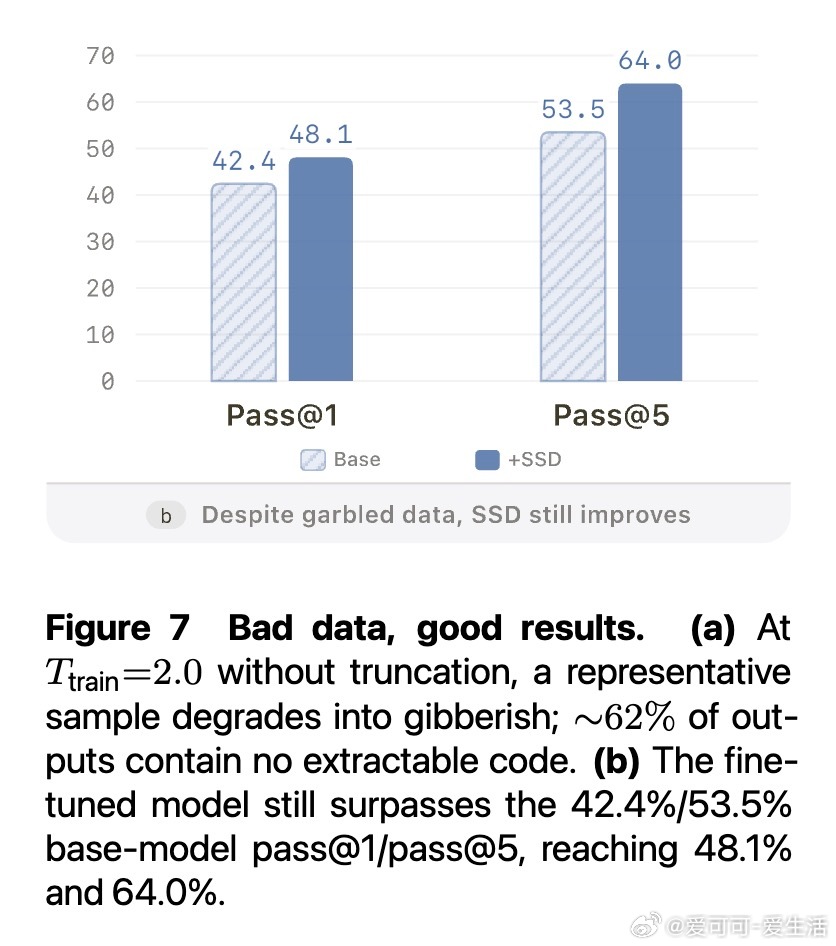
这项工作真正留下的遗产是:强模型内部存在被固定解码策略压抑的潜在能力,而分布重塑本身就是一种可提取的学习信号——即便训练数据 62% 是乱码,模型仍能提升。它为后来者打开的新门是:无需验证器、教师或强化学习的自我进化路径,以及将解码配置设计纳入训练信号设计的新视角。但尚未跨过的门槛是:方法目前仅在代码生成领域得到深入验证,训练数据域外的能力权衡在小模型上尚不稳定,且理论分析依赖局部理想拟合近似,与实际训练动态的差距仍待填补。
arxiv.org/abs/2604.01193
机器学习 人工智能 论文 AI创造营