[LG]《TurboAngle: Near-Lossless KV Cache Compression via Uniform Angle Quantization》D Patel [LLMs Research Inc.] (2026)
大语言模型推理时,KV缓存随序列长度线性膨胀,已成为长上下文场景的内存瓶颈。现有量化方法直接压缩原始激活值,却面临离群值、通道分布差异和非高斯分布三重困境,不得不依赖逐通道校准数据来补偿——这在频繁更新模型或边缘部署场景中代价高昂。
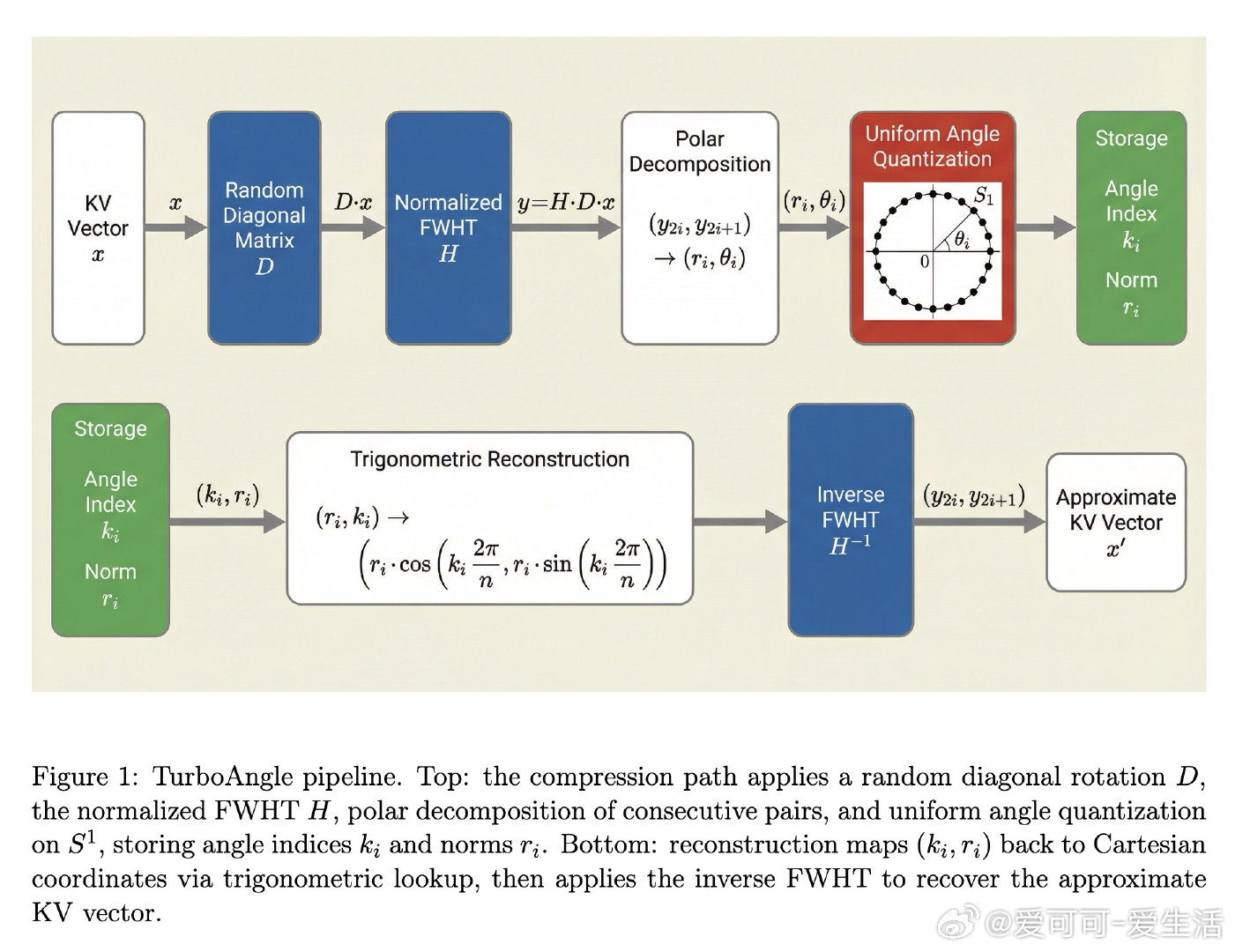
本文的核心洞见是:把"如何均匀量化分布不规则的数值"重新看作"先找到一个分布天然均匀的坐标系,再用最优量化器"。具体操作是在随机符号旋转后施加快速Walsh-Hadamard变换,使相邻元素对的角度在单位圆上趋近均匀分布——均匀分布对应的最优量化器恰好就是等间隔划分,无需任何校准。进一步地,对各层独立配置K/V码本大小,并对K范数用8位线性量化、对V范数用4位对数空间量化,形成零校准的端到端压缩方案。
这项工作真正留下的遗产是:证明了"构造分布已知的变换域"可以将校准需求彻底清零,同时揭示了K缓存范数比V缓存范数敏感10—20倍这一此前未被报告的不对称性。它为后来者打开的新门是:基于理论分布而非经验统计来设计量化器的方法论路径。但尚未跨过的门槛是:仅用困惑度在单一数据集上评估,下游任务表现与长上下文基准仍是未解之题。
arxiv.org/abs/2603.27467
机器学习 人工智能 论文 AI创造营