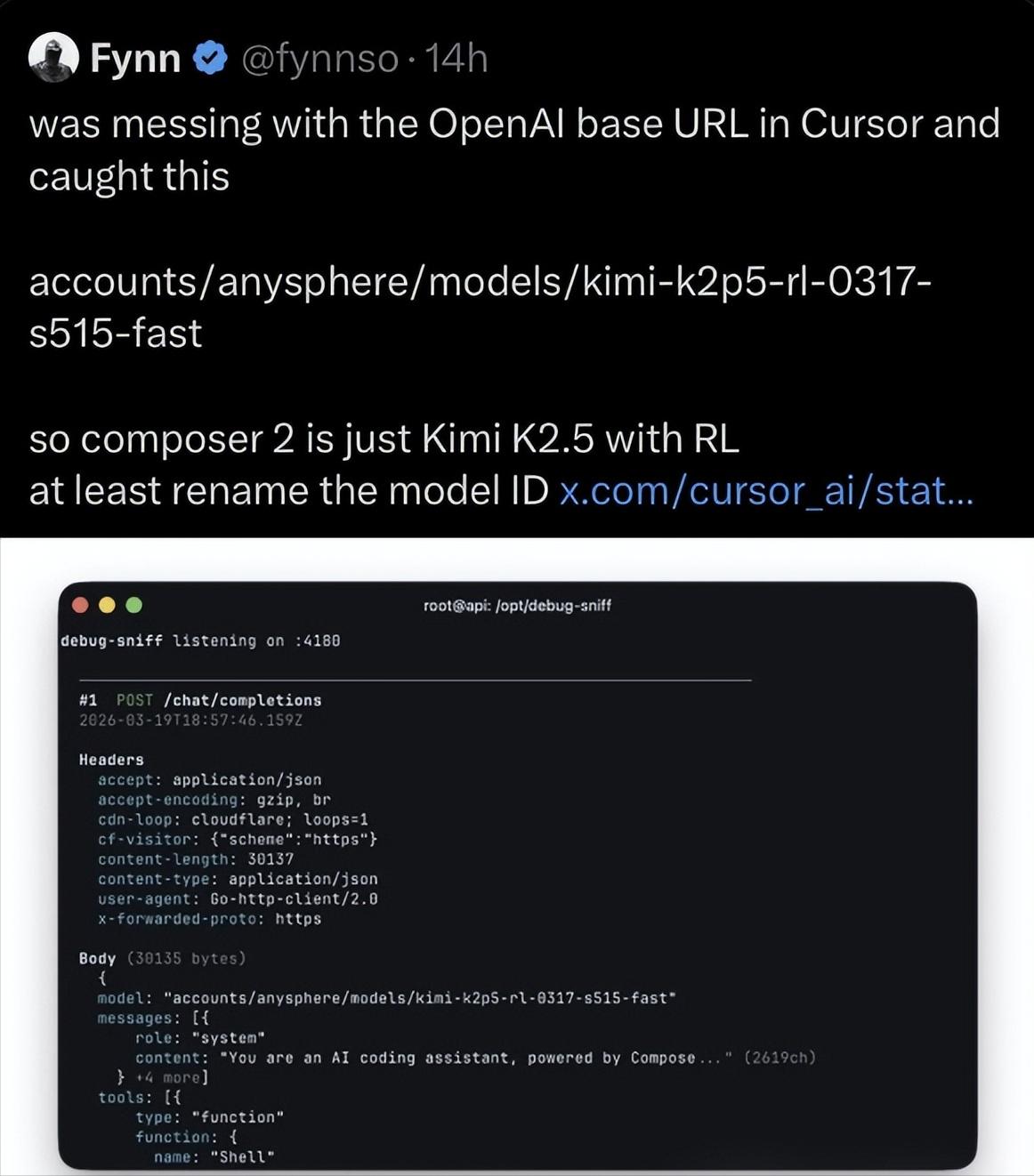
Cursor这次翻车,不是因为用了开源模型,而是因为明明用了中国模型,却还想把功劳全算在自己头上。 事情闹大,是有人在调用Cursor新模型接口时,系统日志里看到了“Kimi K2.5”。这名字不是Cursor自己的,而是中国AI公司月之暗面的模型。问题一下就不只是技术选型了,而变成了“你到底有没有把实话说清楚”。 更扎心的是,Cursor发布时讲得特别满,说什么持续预训练、强化学习、编码能力很强,气势拉得很高。结果热度还没散,截图就把场子砸了。连马斯克都跑出来评论,最后Cursor也只能认错。 其实用中国开源模型,没什么丢人的。现在很多美国AI公司都在这么干。原因特别现实,自己从零训练大模型太烧钱,几千万美元的算力成本不是谁都扛得住。创业公司最省事的路子,就是挑一个现成又能打的开源底座,直接往上做产品。 偏偏中国这批开源模型,正好卡在最实用的位置。性能够强,门槛够低,授权还相对宽松。谁拿去做应用,都能少走很多弯路。Cursor能看上Kimi K2.5,本身就说明这个模型确实硬。 所以这事真正有意思的地方,不是Cursor撒谎本身,而是它把行业里那层大家心里都知道、嘴上不说的窗户纸捅破了。很多人以为自己在用硅谷最火的AI产品,实际上后台跑着的,很可能是中国模型。 表面看,台前还是美国公司在开发布会、拿融资、抢市场。往里一扒,底层能力已经悄悄换了。用户看到的是Cursor,感受到的是流畅和聪明,背后真正出力的,却可能不是它自己。 中国公司把模型开源,也不是图热闹,说白了就是跑渗透。不开门店,不砸广告,不拼海外品牌,直接让全球开发者下载、接入、传播,速度反而更快。谁的模型好用,谁就能先钻进别人的产品里。 这才是最厉害的地方。很多普通人根本不知道自己天天在用的写作工具、代码助手、翻译软件,背后靠的是谁训练出来的模型。牌子没挂出来,技术已经先到位了。