《What Makes 5% of AI Agents Actually Work in Production?》
创业者们常以为自己在做AI产品,实际上是在做“上下文选择系统”。最近在旧金山,有一场汇集Uber、WisdomAI、EvenUp和Datastrato工程师的圆桌,讨论从提示工程转向“上下文工程”、推理架构设计及大规模企业AI代理的落地难题。
现实很残酷:95%的AI代理在生产环境中失败,不是因为模型不够智能,而是缺少坚实的“脚手架”——上下文工程、安全设计、记忆机制和权限治理。这就像有人说:“基础模型是土壤,上下文是种子。”种子不好,长不出好果实。
关键洞见:
- 微调很少是必要的,检索增强生成(RAG)是主流,但多数RAG系统要么索引过多导致模型混淆,要么索引不足信号匮乏,还常因混合结构化与非结构化数据导致嵌入失效。
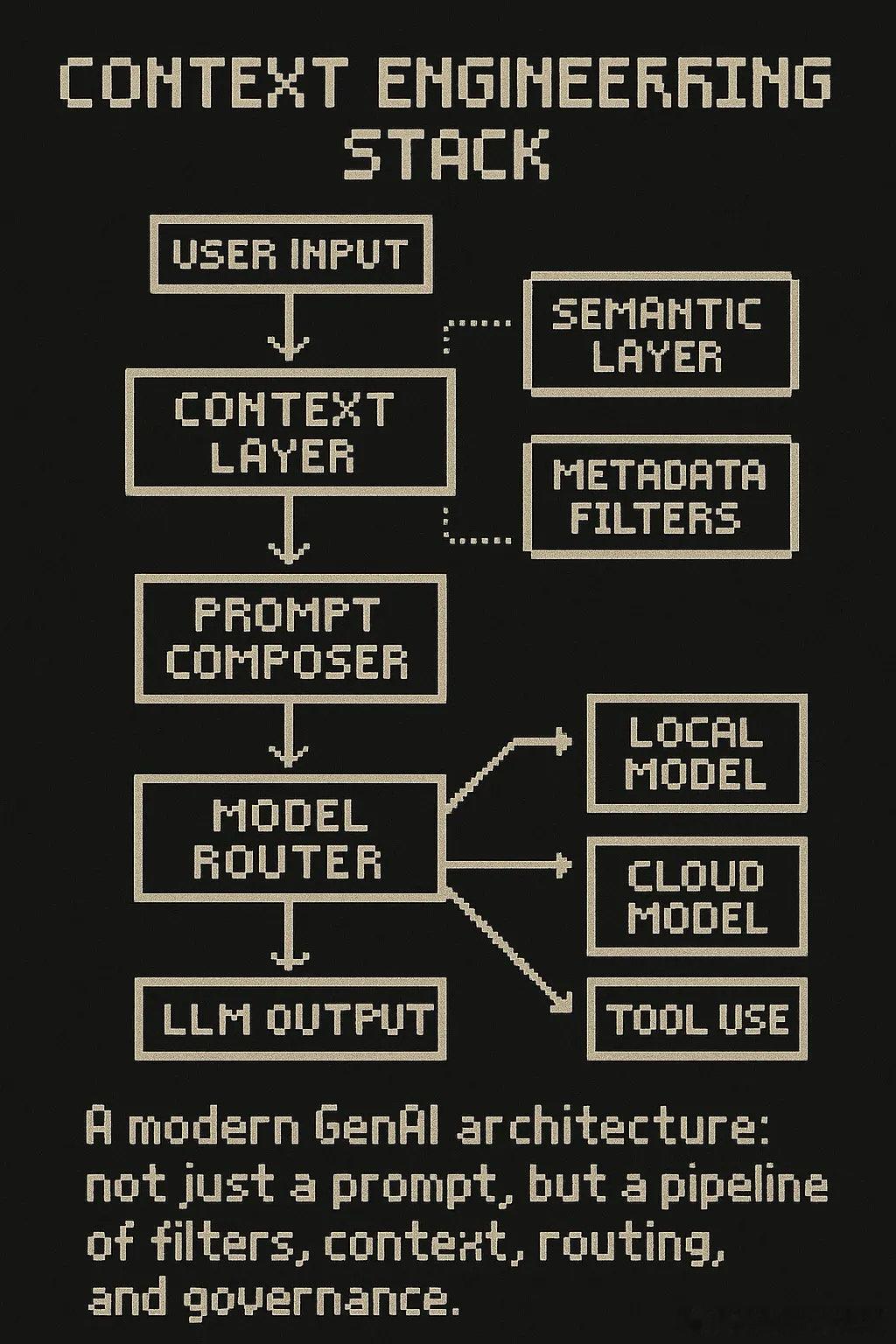
- 上下文工程等同于LLM的“特征工程”:选择上下文=特征筛选,验证上下文=类型和时效校验,上下文可观测性=追踪输入对输出的影响,元数据增强=类型化特征+条件。
- 成功团队构建双层架构:语义层负责向量搜索,元数据层执行基于文档类型、时间戳、权限的过滤,确保检索不仅是“相似内容”,而是“相关结构化知识”。
- 生产环境中,文本转SQL极难落地,因自然语言歧义大,业务术语专业,模型必须依赖详尽的上下文工程、业务词汇表、查询模板及语义验证,且构建持续反馈机制。
- 安全与权限管理是部署最大障碍:必须实现输入-输出溯源、细粒度访问控制和个性化响应,保证同一问题不同角色得到不同答案,防止数据泄露和合规风险。
- 用户信任是AI推广的核心阻力,尤其在安全、财务、医疗等敏感领域。5%成功的AI代理都有“人类在环”设计,AI作为辅助而非决策者,支持人类校验和纠错。
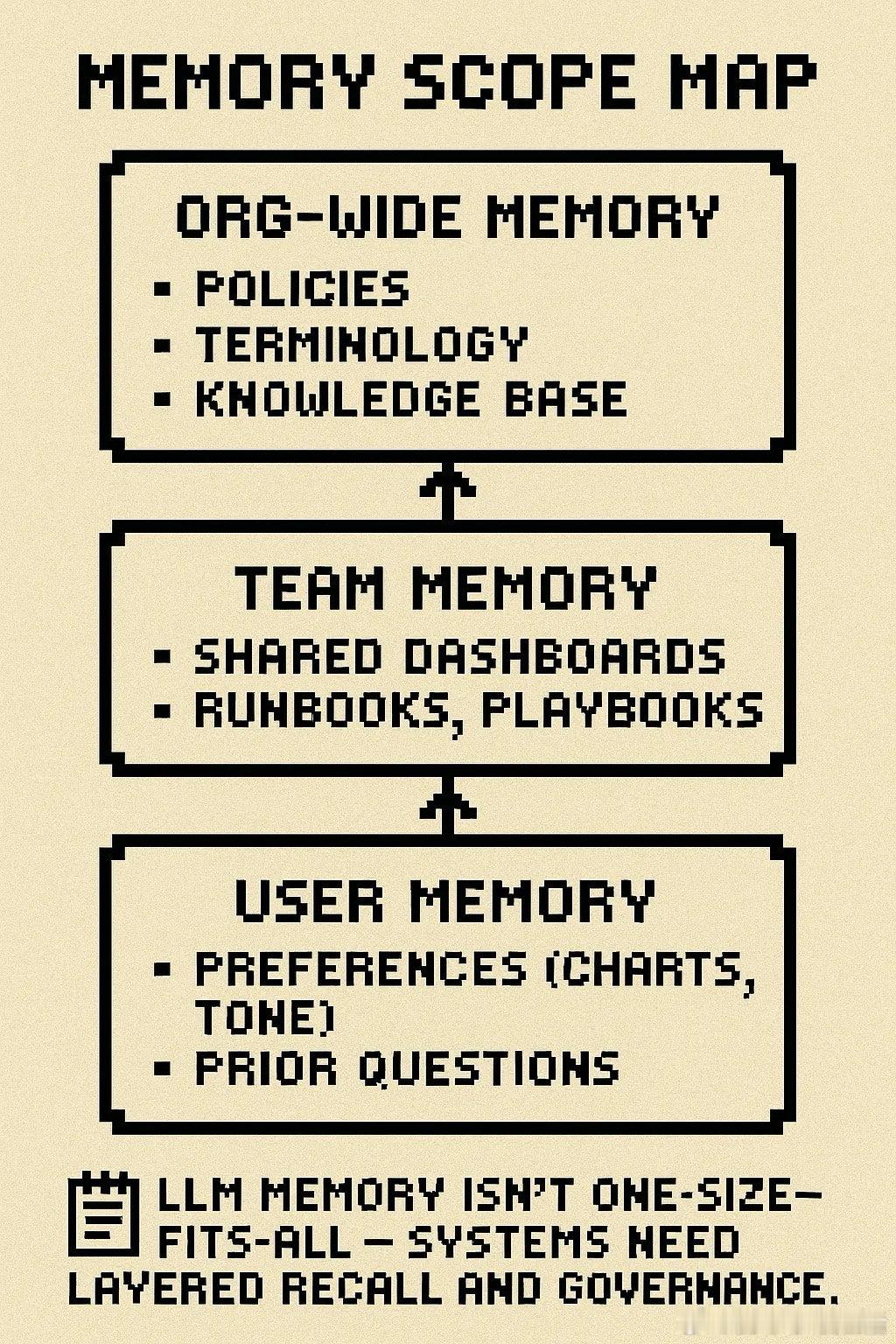
- 记忆不是简单功能,而是设计决策,涉及用户偏好、团队常用查询、组织知识。最佳实践是将记忆抽象为可版本化、可组合的上下文层,而非硬编码或本地存储。
- 模型编排逐渐成为标配,根据任务复杂度、延迟要求、成本敏感度和合规性自动路由请求,不同任务调用不同模型,类似编译器运行DAG决策流。
- 聊天界面并非万能,自然语言适合降低复杂工具的学习门槛,但用户常需GUI做精细调整。设计应基于用户意图,区分情绪化客服与探索型复杂查询。
- 未来关键基础设施包括上下文质量、记忆设计、编排可靠性和信任体验,而非单纯依赖模型能力。创业者应问自己:我的上下文预算是多少?记忆边界在哪里?能否追踪响应来源?如何智能路由?用户会信任我的系统吗?
如果你正构建这类系统,尤其在基础设施或垂直领域,欢迎交流。上下文工程不仅是技术难题,更是AI产品能否真正落地的核心。
原文链接:
motivenotes.ai/p/what-makes-5-of-ai-agents-actually

![最火ai排名,你平常用哪个[思考]](http://image.uczzd.cn/13567813052405002715.jpg?id=0)