Nanonets-OCR2:颠覆传统OCR,智能将文档转为结构化Markdown
Nanonets推出的OCR2系列,是业内领先的图像转Markdown模型,不仅提取文本,更实现智能内容识别与语义标注,极大提升LLM后续处理效率。
核心亮点:
- LaTeX公式识别:自动区分行内与块状公式,精准转换为LaTeX格式。
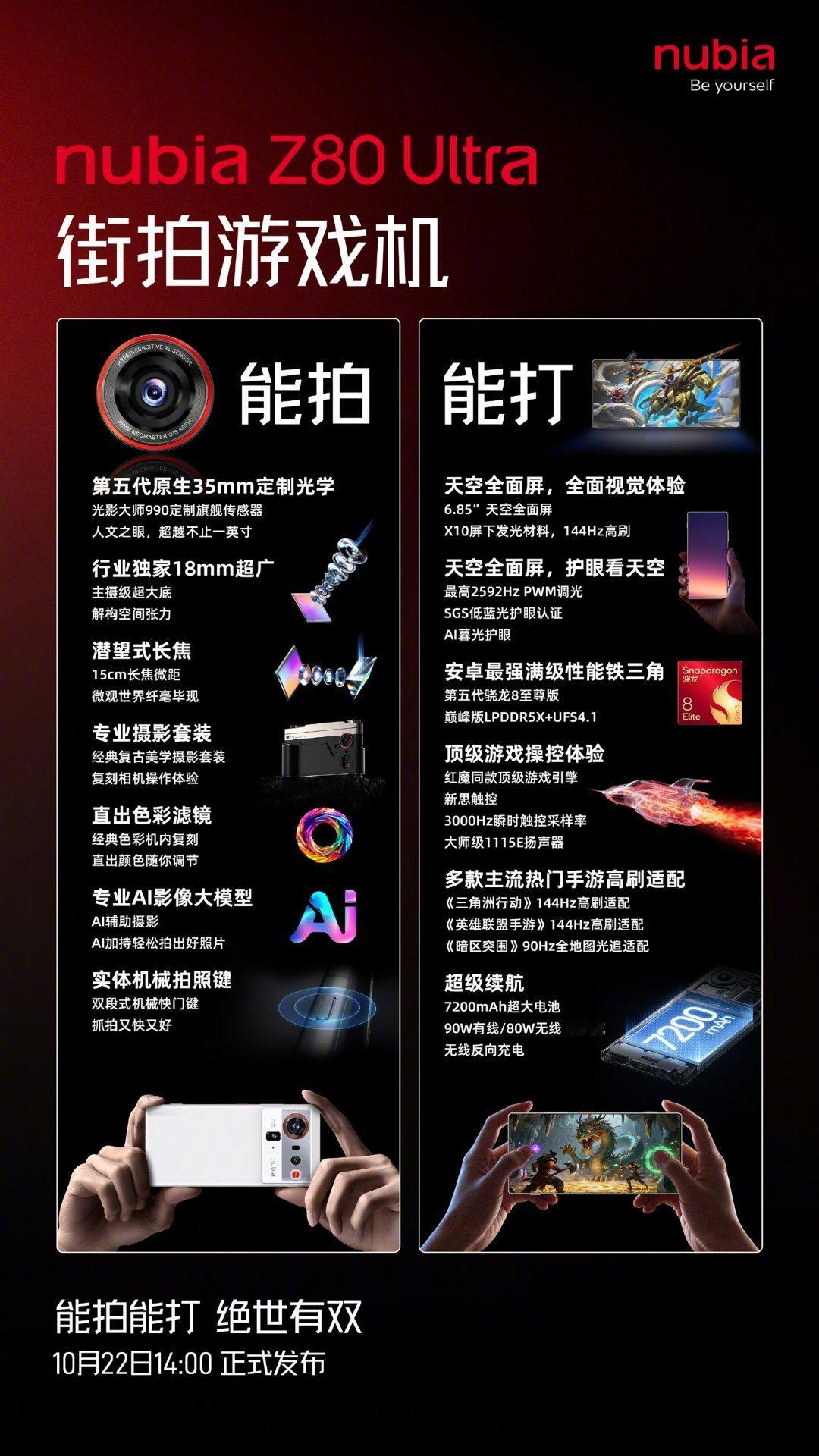
- 智能图片描述:为无标题图片生成结构化描述,支持logo、图表、流程图等多种类型。
- 签名与水印提取:准确识别文档中的签名和水印,分别用专属标签隔离,方便法律与商务文件处理。
- 智能表单控件处理:将复选框和单选按钮标准化为Unicode符号(☐、☑、☒),统一解析。
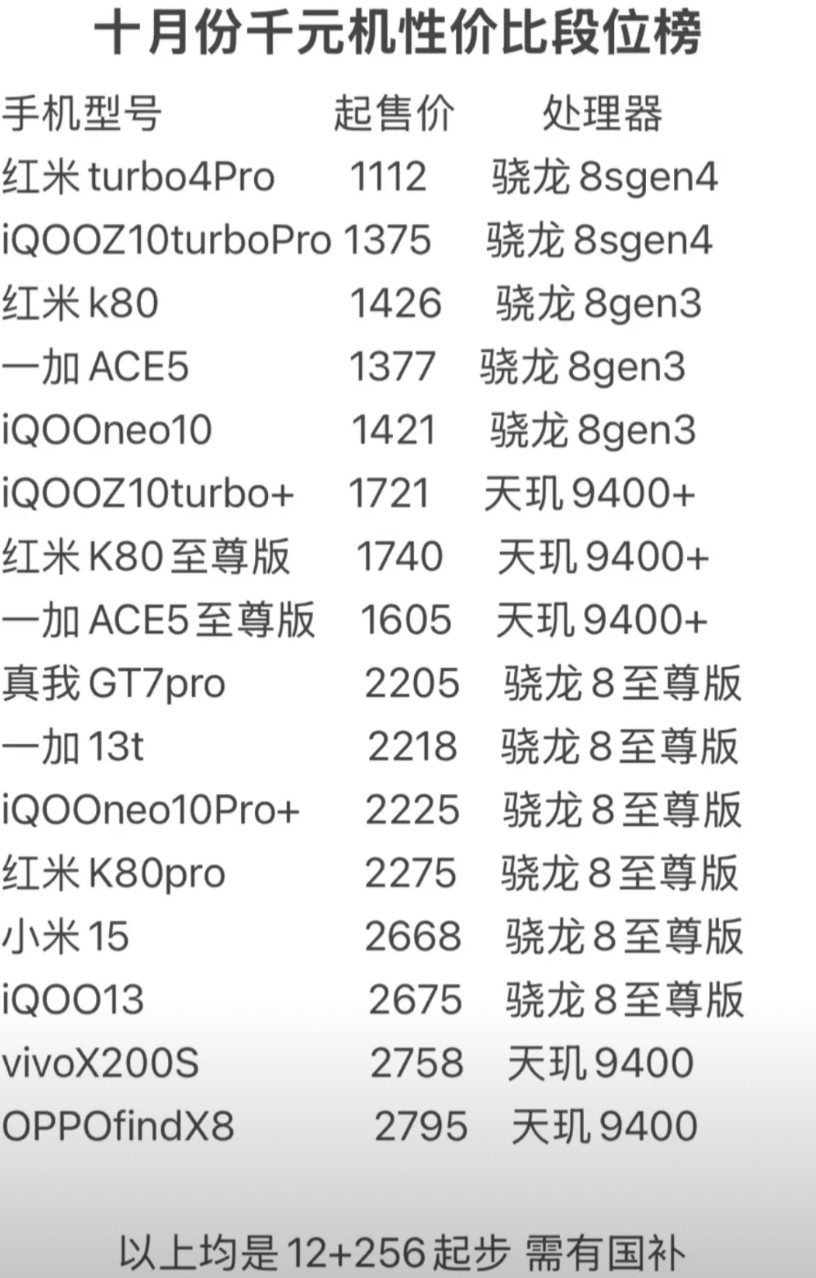
- 复杂表格与图表提取:支持复杂表格转Markdown和HTML,流程图和组织架构图转Mermaid代码。
- 多语言与手写文档:覆盖英语、中文、法语、西班牙语、日语等多语种,且对手写文档同样友好。
- 视觉问答(VQA):能直接回答文档内问题,若无答案则回复“不提及”。
实用建议:
- 提升图片分辨率能显著提高准确率。
- 金融等复杂表格文档推荐使用专门优化的“Markdown (Financial Docs)”模式。
- 通过API、transformers库或vLLM均可灵活调用。
Nanonets-OCR2不仅是OCR,更是智能文档理解的强力引擎,助力自动化办公、文档分析和知识管理进入新阶段。
详细内容及开源模型:huggingface.co/nanonets/Nanonets-OCR2-3B