用代码助手,才知道tokens不经烧,模型不经造。象有些模型,在代码助手的场景,根本就没有用了。
比如,deepseek r1 32b,去年的网红,今年就真的过气了。这个模型的上下文空间只有32K。去年看着觉得不小了,因为之前的模型,上下文空间都是4096,8192之类的。
但是在代码助手的场景,去年的网红deepseek r1 32B,现在是一点用都没有。因为claude 说句“你好”,内置的tools就占了25k左右的上下文。对话三轮估计就会溢出。
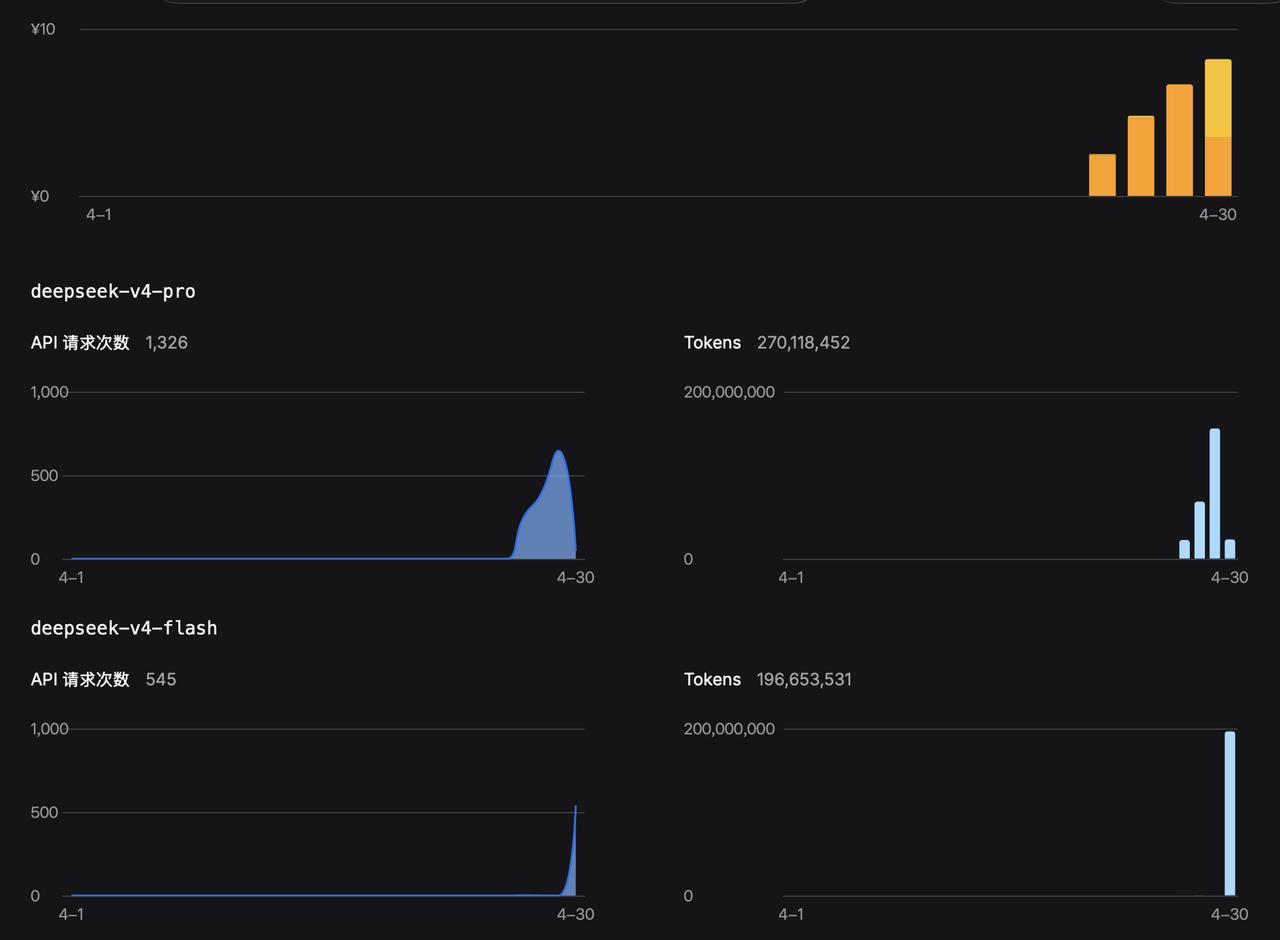
代码助手的场景,最少也得120k上下文。128k其实都是不及格的水平,用起来非常凑合。一般要200k。我用deepseek经常会达到300k上下文。
当然,这跟各种代码助手滥用历史消息有关。比如,它调用一次工具,产生大量的启动信息,它会把所有信息,都堆在历史信息里面。以后每轮对话都带着它。无论那种代码助手,都是如此。上下文暴涨是常态。有的人可能说,装skills会改善它。不见得,可能装skills之后,上下文占用更多了,因为skills本身也要占用上下文。
skills和tools的区别,其实本质上都是提示词。skills比tools更低一个级别。
代码助手,有大约十来个tools,其中有一个是调用skill。大模型用这个工具,就可以把skill读入,然后执行它。
代码助手这类智能体是需要长上下文的。大部分大模型具备128k以上长上下文,也就是一年左右的随时间。也就是说,所有的代码助手,年龄其实都不超过一岁,大家都是瞎子,claude code不过是个幸运的瞎子,别把它吹上天。还早着呢。
虽然大模型是大脑,但是智能体,将来也不可忽视。智能体决定大模型怎么用。
大模型相当于cpu,而智能体则是操作系统和编译器。
因此,代码助手这类智能体,未来是各家大模型产商的竞争关键。得智能体者的天下。