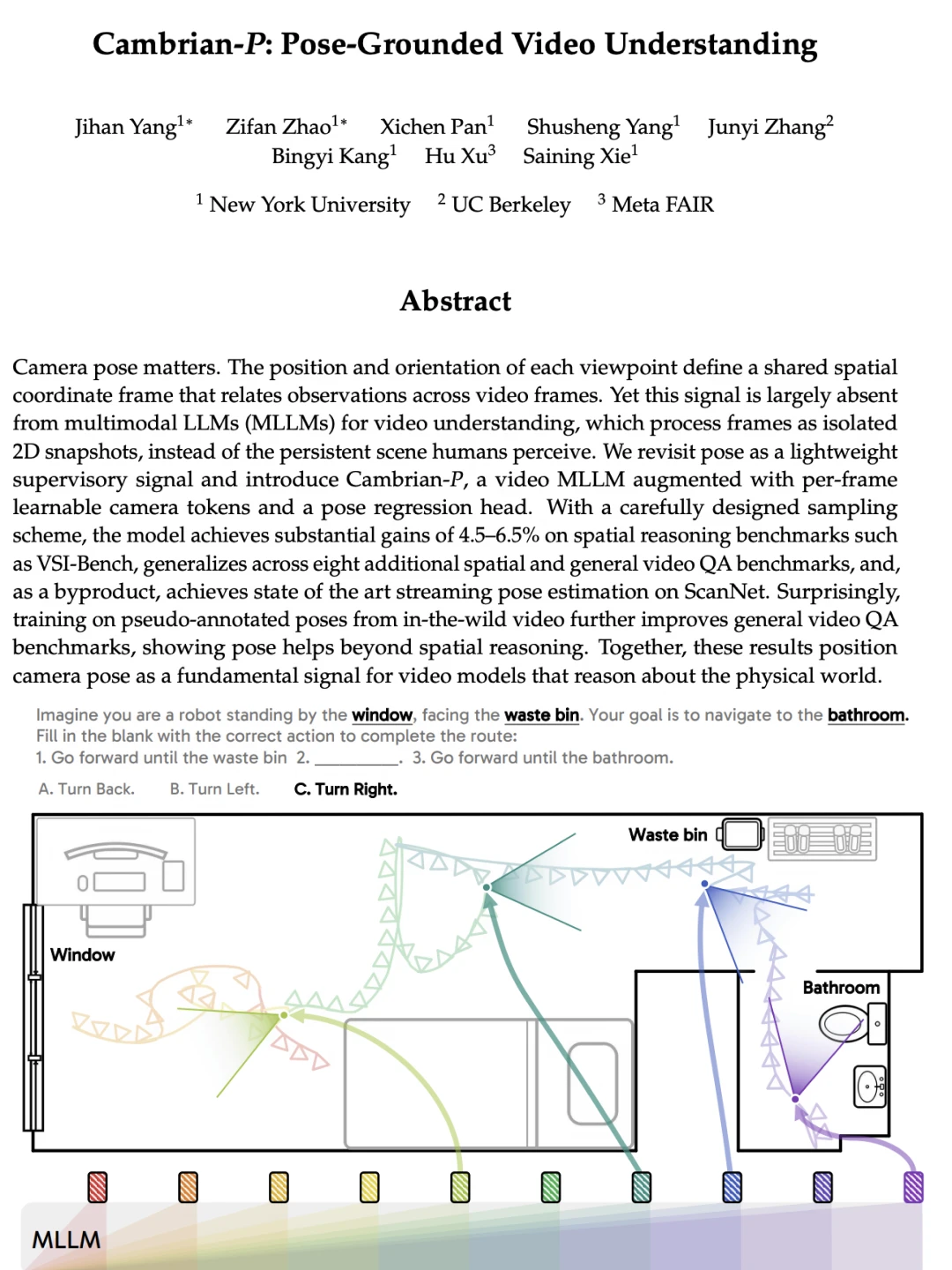
多模态大模型在处理视频时,常常把视频看成一系列独立的2D图像,难以准确把握物体的前后左右和空间关系,空间推理能力相对有限。
NYU谢赛宁团队联合UC Berkeley和Meta FAIR最近提出 Cambrian-P 架构,尝试通过引入相机位姿(Camera Pose)信息来增强模型的空间理解能力。
主要改进点:
🔸将相机位姿作为一种几何信号引入模型,每帧添加少量可学习Pose Token,整体改动较小
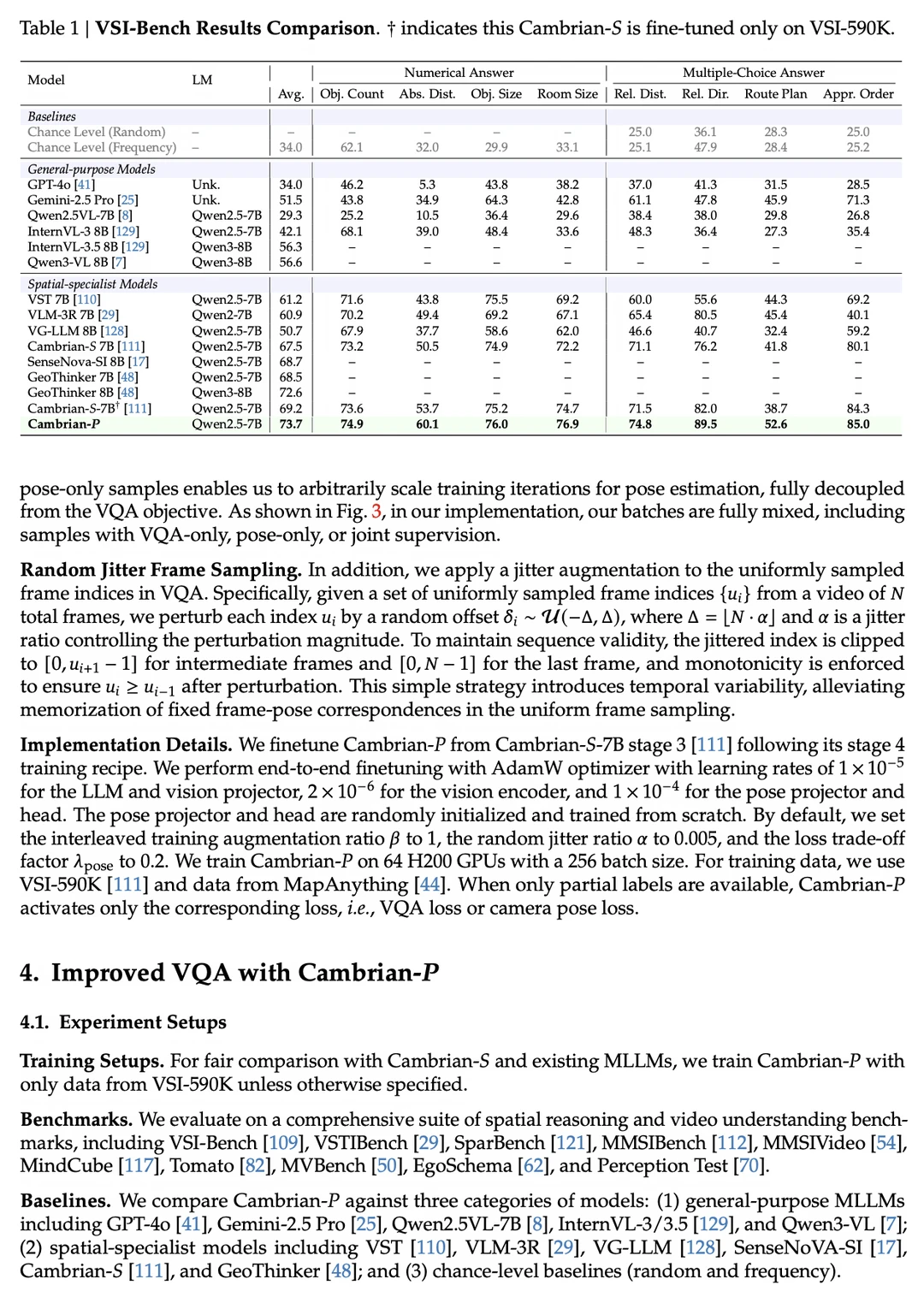
🔸在空间推理基准VSI-Bench上,相比基线模型提升约4.5%-6.5%
🔸在多个通用视频问答基准上也表现出更好的泛化效果
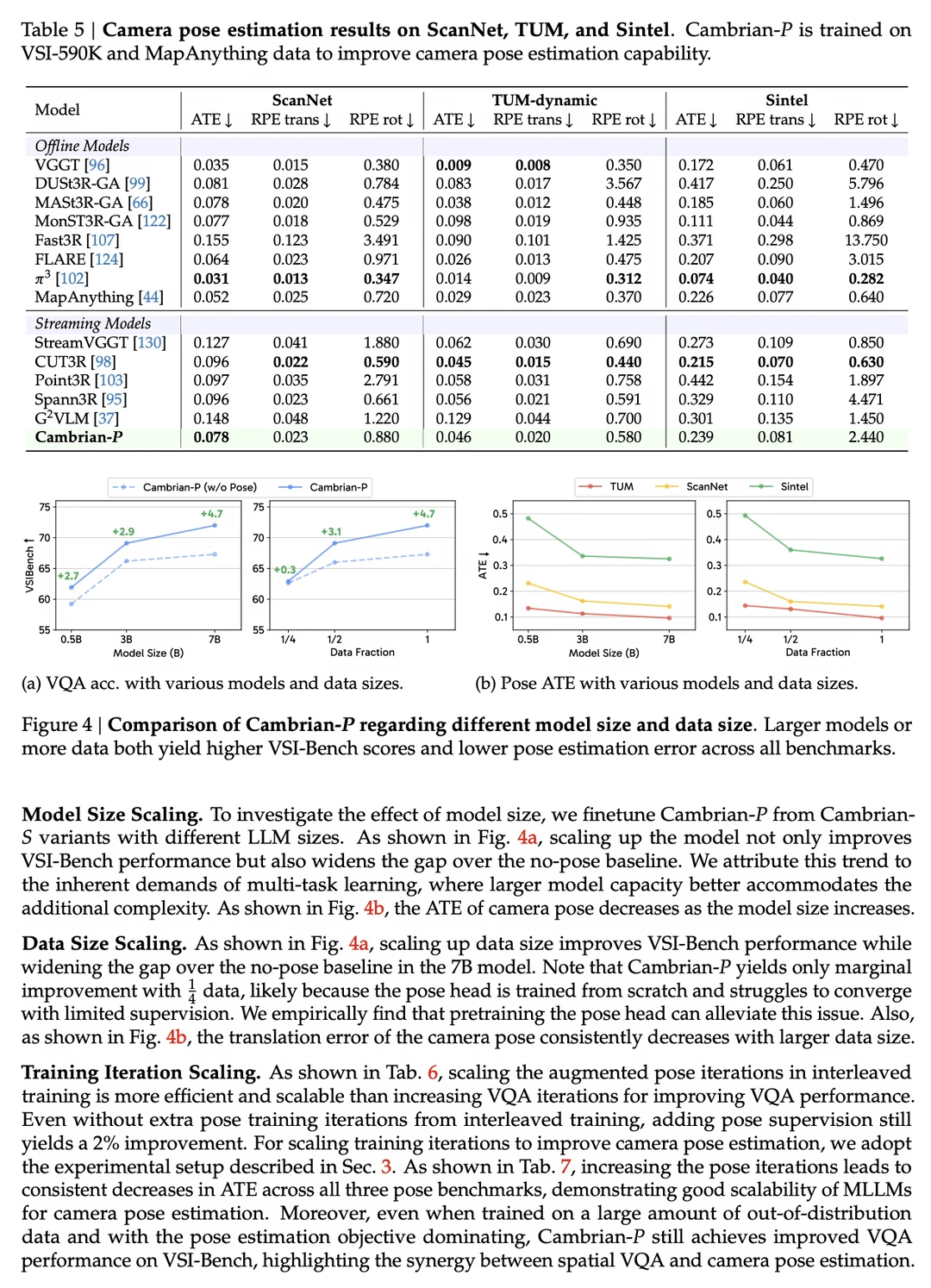
🔸同时在ScanNet数据集的流式相机位姿估计任务上取得较好结果
论文的核心思路是相机位姿可以作为帮助视频模型更好地对齐到物理世界的有用信号,而不仅仅依赖单纯扩大模型规模。
这项工作对自动驾驶、具身智能、AR/VR等需要强空间理解的应用场景有一定参考价值。论文已开源,感兴趣的朋友去戳原作细细品读!