在处理超长上下文时,Transformer 的 KV Cache 显存暴涨、推理变慢一直是业界的切肤之痛。
来自牛津大学 OATML 实验室、NVIDIA以及 Technion 的联合研究团队发表了突破性论文《Training Transformers for KV Cache Compressibility》,从训练源头为大模型「瘦身」开辟了新路径!
当前长文本需求井喷,但 KV Cache 随文本长度线性暴增($$\mathcal{O}(N$$),极易导致显存溢出。现有的「事后压缩」(如 Post-hoc 量化或剪枝)属于「硬着陆」,如果模型原生表征不友好,强行压缩会导致性能急剧崩塌。
团队首次从数学上形式化了「KV 可压缩性」。
他们惊人地证明了:KV Cache 是否好压缩,完全取决于模型在训练中习得的「内部表征」! 即使实现完全相同的功能,模型也可能走向「本质不可压缩」的死胡同。
因此,必须在训练阶段进行干预。
团队提出 KV-CAT(KV Compression Aware Training) 持续预训练方法:
🔸核心机制
在训练时引入轻量 router,对部分 forward pass 主动掩蔽(mask)一定比例的 KV slots,制造信息瓶颈;同时通过 masked forward 与 dense forward 的自蒸馏,迫使模型学习对压缩高度鲁棒的内部表示。
🔸关键优势
推理时无需改动模型架构,即可显著提升各类现有 post-hoc 压缩方法的效果。
实验显示(基于 Qwen2.5 系列):
1.未压缩性能基本持平或略有提升
2.压缩后 Needle-in-Haystack 检索准确率最高提升 +68%
3.LongBench 长上下文任务最高提升 +39%
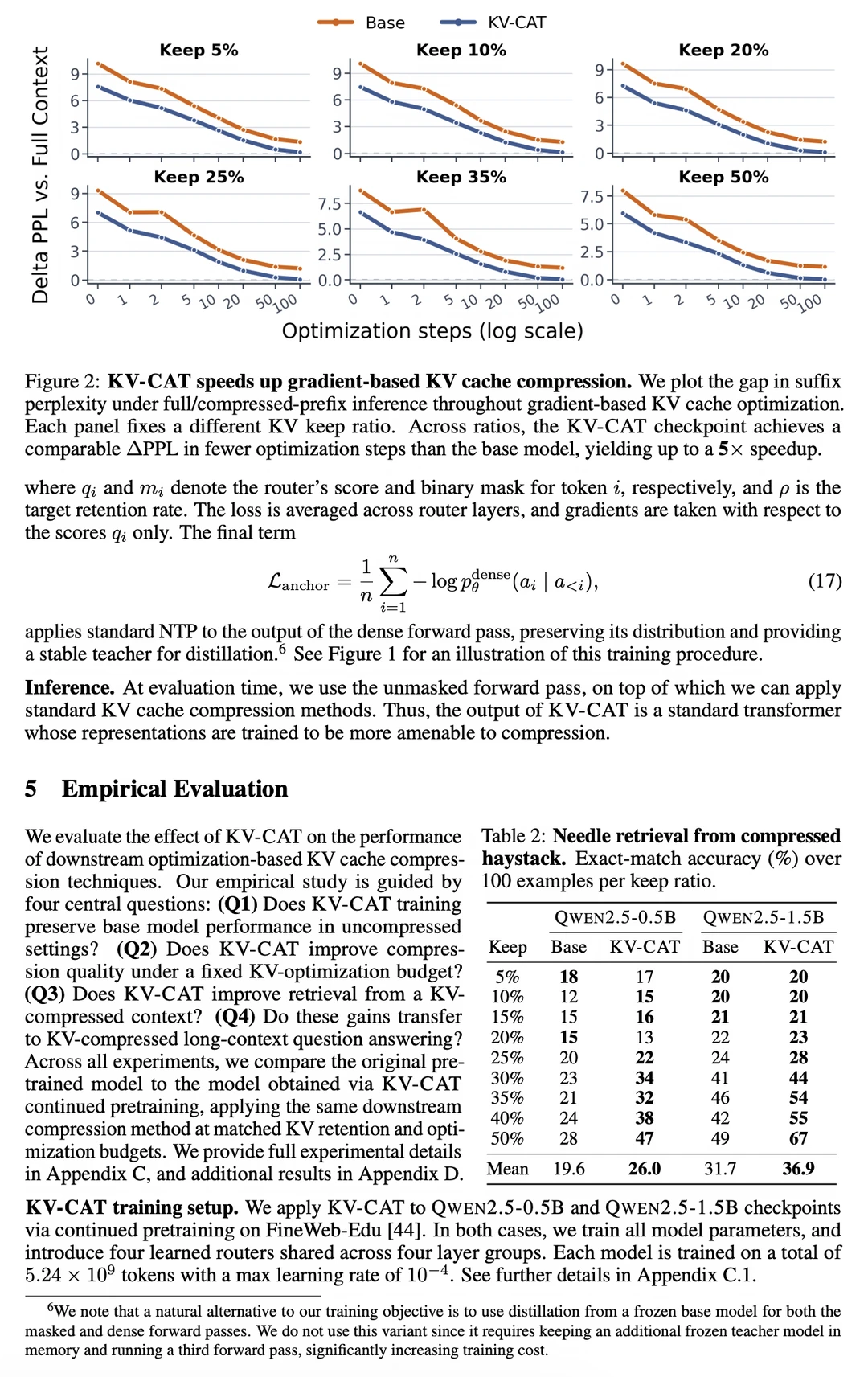
4.优化-based 压缩方法的收敛速度最高快 5 倍
这项研究彻底改变了「先训练、后压缩」的传统被动思路,通过在训练期注入压缩感知,让大模型「天生」自带高效压缩体质,为长上下文大模型在有限硬件资源下的平民化落地提供了坚实的理论与工程支撑!
对追求极致长上下文效率的团队(如 RAG、agent、长文档建模)非常有参考价值。
如果你觉得对你有用的话 ~ 欢迎点赞收藏并分享给你的盆友们~非常感谢!