【低延迟语音 AI 背后:OpenAI 重构 WebRTC 分层设计思路】
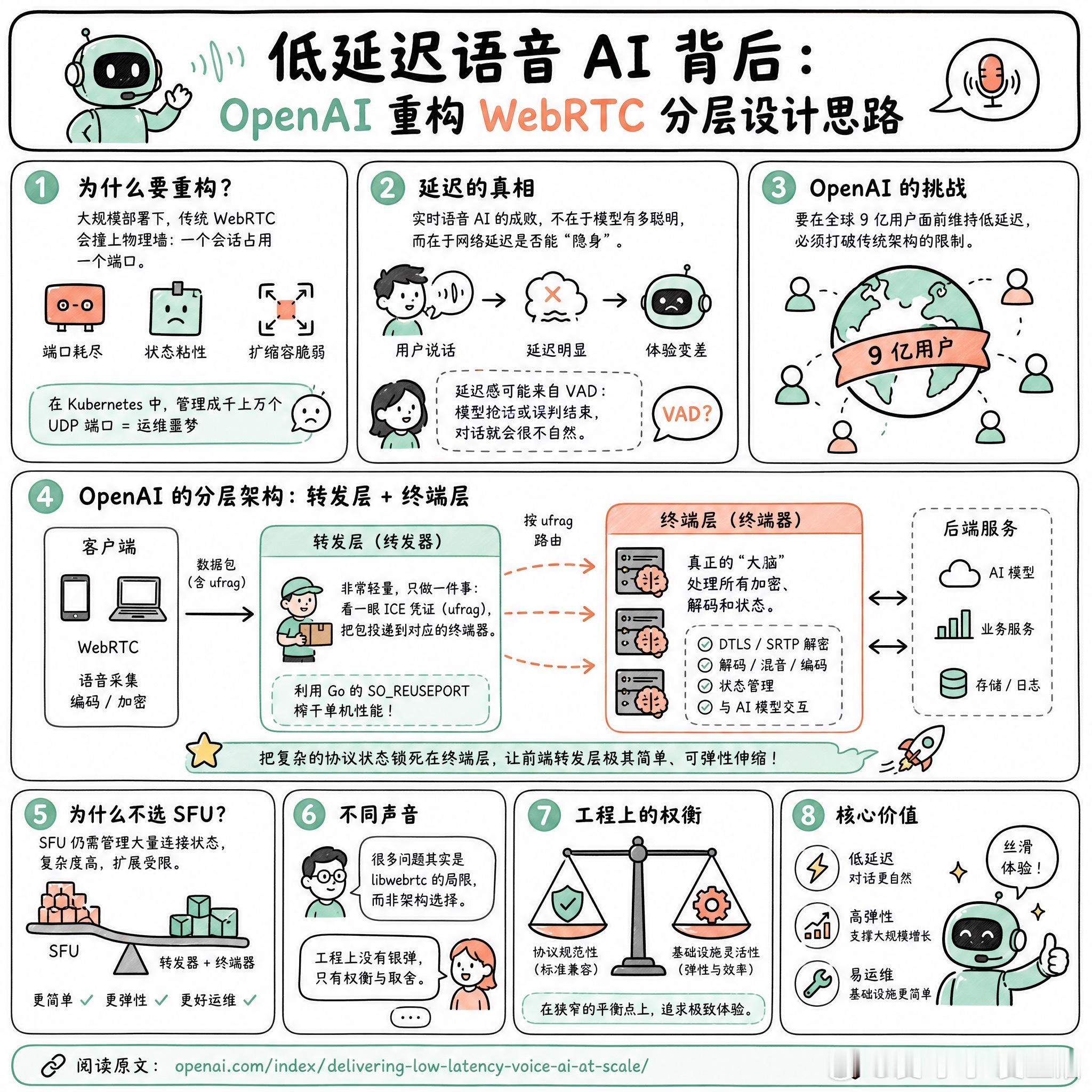
快速阅读:OpenAI 通过将 WebRTC 拆分为“转发层”与“终端层”的架构,解决了大规模部署下的端口耗尽与状态粘性问题。这种设计既保留了标准协议的兼容性,又让复杂的媒体流能像普通微服务一样在 Kubernetes 中弹性伸缩。
实时语音 AI 的成败,不在于模型有多聪明,而在于网络延迟是否能“隐身”。如果用户说话时有明显的停顿或回声,再强大的逻辑也会显得笨拙。
OpenAI 的挑战在于规模。要在全球 9 亿用户面前维持低延迟,传统的 WebRTC 模式会撞上物理墙:一个会话占用一个端口。在 Kubernetes 环境下,管理成千上万个 UDP 端口简直是运维噩梦,既难安全审计,又让自动扩缩容变得极其脆弱。
有网友提到,这种延迟感有时并非来自网络传输,而是语音活动检测(VAD)的问题。当模型太快抢话,或者用户在思考时被误判为结束,对话就会变得极其不自然。
为了绕过这些坑,OpenAI 没选主流的 SFU(选择性转发单元)架构,而是搞了一套“转发器 + 终端器”的组合。转发器非常轻量,只负责看一眼数据包里的 ICE 凭证(ufrag),然后像快递员一样把包投递到对应的终端器。终端器才是真正的“大脑”,它处理所有的加密、解码和状态。
这种做法很巧妙。它把复杂的协议状态锁死在终端器里,而让前端的转发层变得极其简单,甚至可以利用 Go 语言的 `SO_REUSEPORT` 来榨干单机性能。
不过,也有开发者对此持有不同看法。有观点认为,OpenAI 遇到的很多问题其实是 `libwebrtc` 本身的局限,而非架构选择的问题。
这种工程上的权衡很有意思。当我们需要极致的响应速度时,往往得在协议的规范性与基础设施的灵活性之间,找一个极其狭窄的平衡点。
openai.com/index/delivering-low-latency-voice-ai-at-scale/