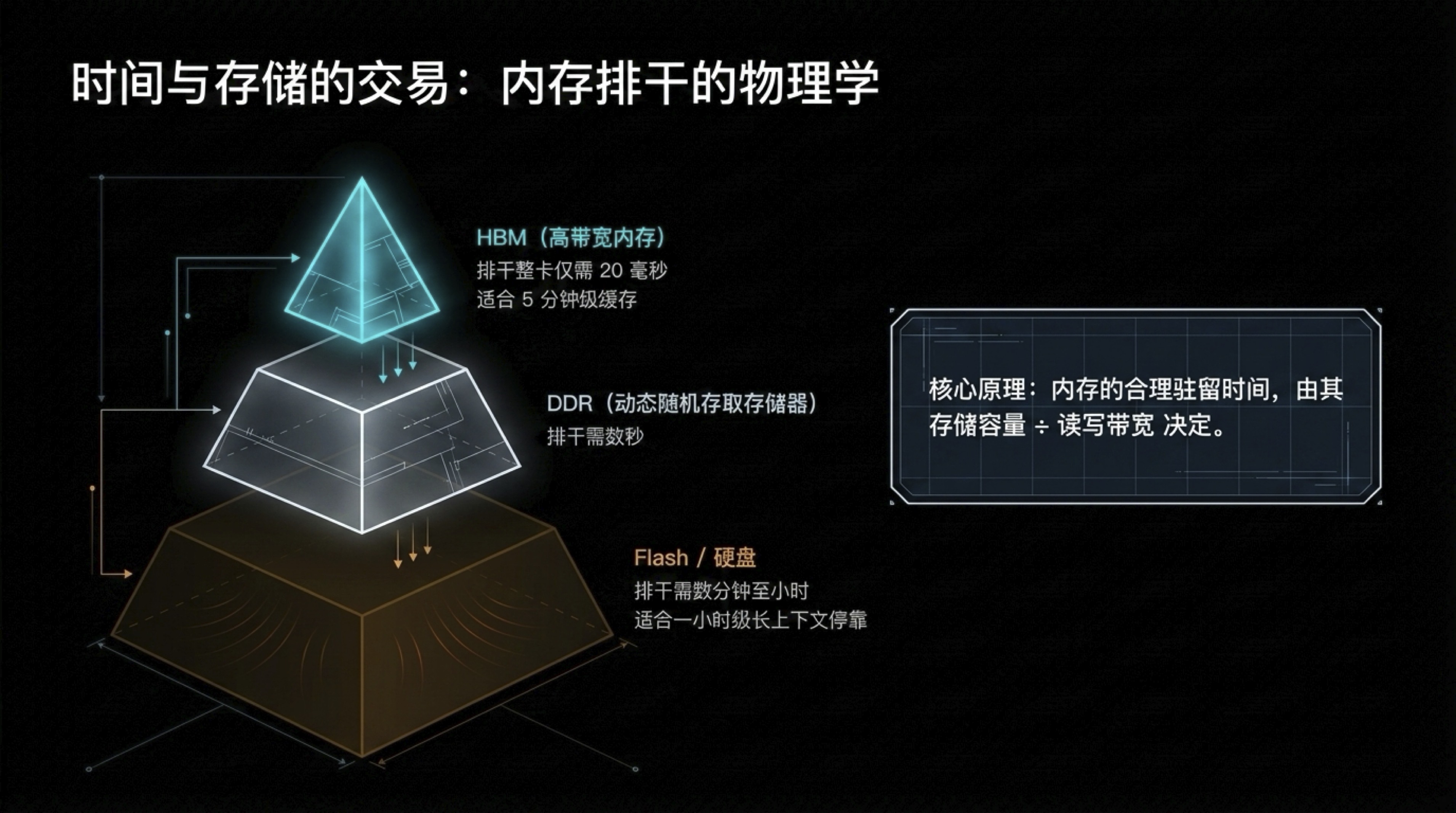
是什么卡住了模型的上下文长度?不是计算,而是内存带宽瓶颈!Dwarkesh 最新播客首次启用的黑板讲座 - 嘉宾Reiner Pope 曾在 Google 负责 TPU 架构,现在创立了芯片初创公司 Maddox,他用数学推导解释了 LLM 推理和训练的底层经济学👀
推理一个 token 需要的时长取决于“计算与内存时间“这两个瓶颈中更慢的那个:实际推理时间 = max(T_compute, T_memory)。
在小 batch size 时,内存带宽是瓶颈(要加载全部权重但只服务一个用户);在大 batch size 时,计算成为瓶颈。两者相等的交叉点就是最优 batch size。
计算成本随上下文长度几乎不变(因为注意力的计算量相对权重矩阵乘法很小);但内存带宽成本随上下文长度线性增长(需要加载 KV cache)。
稀疏注意力可以帮助(DeepSeek 论文中是平方根改善),但不是无限的——太稀疏会损失质量。
"我实际上看不到解决内存墙的好路径。HBM 就是现在这个水平,不会大幅改善。"
这直接回应了 Dario Amodei 的观点("不需要持续学习,in-context learning 就够了")——如果你需要等同于"与你工作一个月的同事"的 context,那可能需要 1 亿 token 的上下文窗口,在现有内存架构下成本极高。
内存(HBM)是真正的瓶颈!Pope 的分析从第一性原理证明了 Dylan Patel 反复强调的"DRAM 还要翻 2-3 倍"。内存带宽决定了上下文长度上限、推理成本下界、最优 batch size。SK Hynix、三星、Micron 是直接受益者⚡️