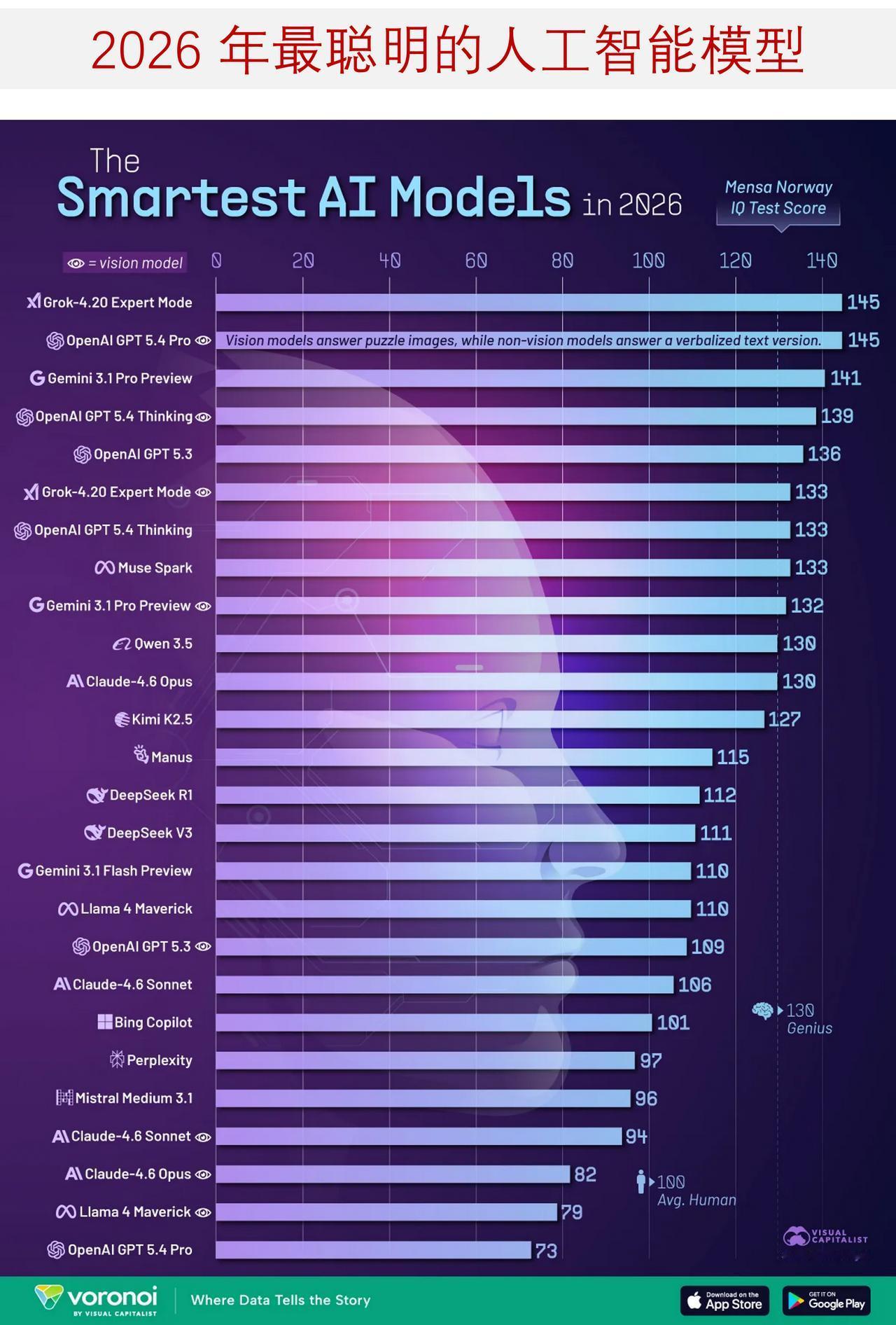
2026 最聪明的 AI 是谁?挪威门萨测试榜单,揭露头部模型真实差距 顶尖人工智能模型的研发竞争,正变得愈发激烈。 下面信息图依托 TrackingAI 的调研数据,对国际上主流 AI 系统进行排名。该榜单以挪威门萨智商测试为测评基准,数据截至 2026 年 4 月。 排名结果既展示了当下的行业领跑者,也反映出头部竞品之间的差距已微乎其微,多款前沿模型扎堆位列榜单上游。 ——榜首并列,竞争白热化 本排名直观呈现了主流 AI 模型在抽象模式识别任务上的表现,以及行业内卷的激烈程度。 如下图所示,当前顶尖模型之间的分数差距极小。 最核心的结论,是头部梯队分数高度接近。 Grok-4.20 专家版 与 OpenAI GPT 5.4 Pro(视觉版)以 145 分并列第一,Gemini 3.1 Pro 预览版以 141 分紧随其后。 分数区间高度收窄,意味着前沿 AI 模型的能力正在快速趋同,榜单名次往往仅由数分之差决定。 相较 2025 年,整体进步幅度同样显著。 去年榜首最高分为 135 分,而今年已达到 145 分,足以体现头部模型在该项测评中的迭代速度。 并非所有厂商都同步跟进迭代。 在主流 AI 研发企业中,Mistral 旗下旗舰模型得分垫底,仅为 97 分,与第一梯队差距悬殊。 ——TrackingAI 测评方式说明 本次测试采用公开版挪威门萨测试,整套试题包含 35 道视觉图形推理题。 非视觉类 AI 模型会接收文字化题干,多模态视觉模型则直接读取原始题图。 因此,该结果仅适用于横向对标参考,不能完全等同于综合智力水平。 由于测试以视觉推理为主,题干呈现形式的不同,也会造成模型得分波动。 ——该测评的参考价值 TrackingAI 排行榜的核心价值,在于提供一套简洁、通用的标准,长期对比各类模型的逻辑推理能力。 平台同时注明:若模型拒绝作答,同一题目最多重复提问 10 次,以最终作答结果计入评分。 即便如此,智商类测评仅能反映 AI 能力的单一维度。 它无法覆盖实际应用中的核心能力,例如代码编写、事实准确性、工具调用、专业领域落地表现等关键指标。