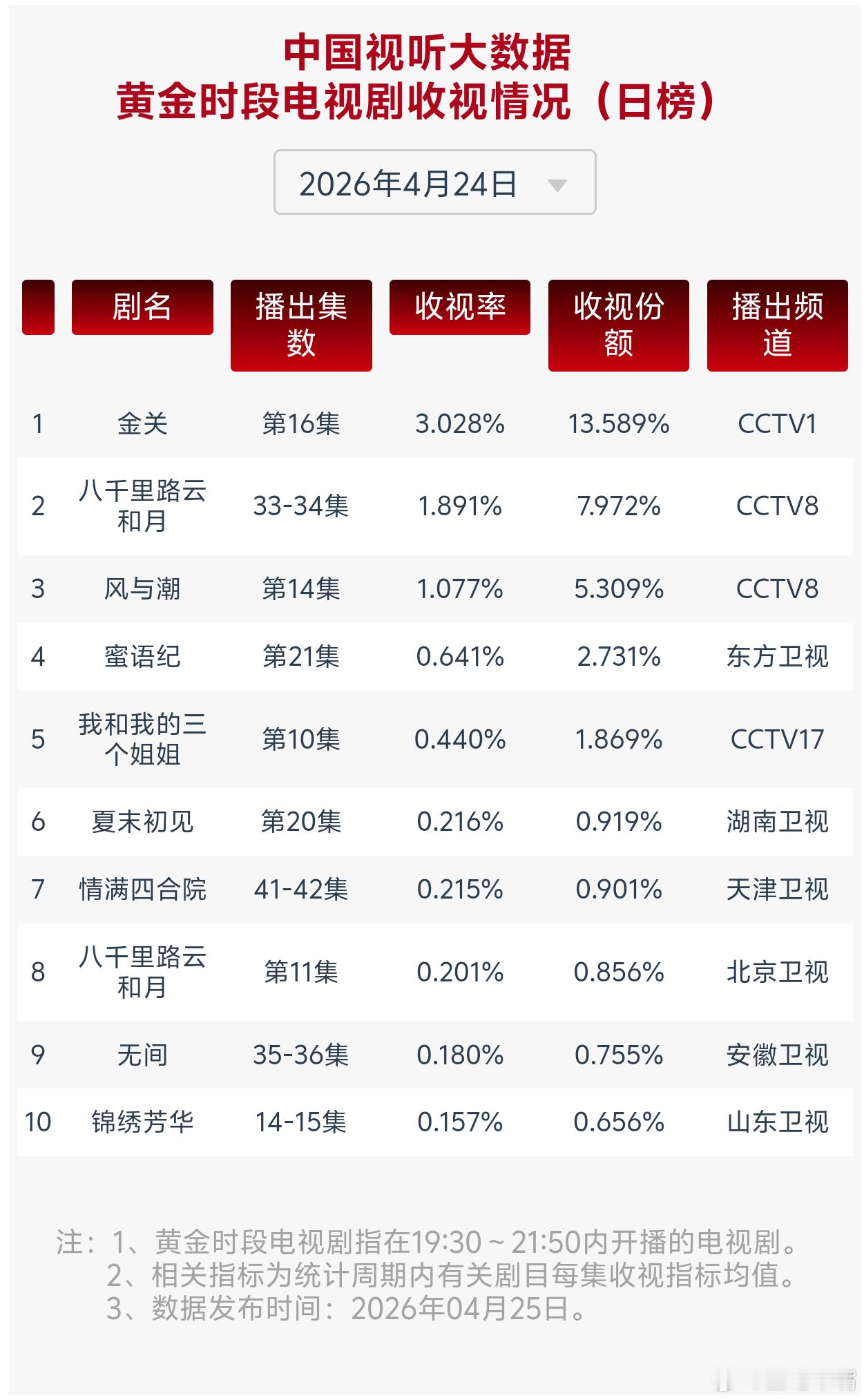
【东吴计算机王紫敬】真正读懂DeepSeek V4:国产化训练从0到1里程碑,战略意义大于性能意义
重要意义:国产开源大模型在国产算力训练适配领域以及百万级上下文能力实现了里程碑式突破。
一、DeepSeek V4首次由华为昇腾芯片参与训练1、国产算力适配:DeepSeek V4 Flash是首个公开说明训练侧使用国产算力的通用大模型,通过三大核心设计实现了去英伟达化的技术布局(1)引入MXFP4 量化感知训练,对MoE专家权重与索引器QK路径实现FP4量化,降低了对NVIDIA FP8生态的绑定,可无缝适配华为昇腾、寒武纪等国产芯片;(2)采用TileLang领域专用语言开发底层算子,脱离CUDA生态强绑定,可跨硬件平台编译,大幅降低向国产芯片的迁移成本;(3)自研MegaMoE2融合内核,实现专家并行的细粒度通信计算重叠,已在华为昇腾平台完成适配跑通,解决了国产硬件环境下MoE模型的通信瓶颈。
二、性能表现:整体跻身全球第一梯队,多项核心指标比肩甚至超越国际顶级闭源模型。1、知识储备:DeepSeek-V4-Pro-Max 在 SimpleQA-Verified 基准上取得57.9分,领先第二名开源模型20个百分点,中文 SimpleQA 得分达84.4,大幅缩小与Gemini-3.1-Pro的差距,MMLU-Pro、GPQA Diamond等教育知识基准均领跑开源赛道。2、推理与代码能力:Pro-Max 版本Codeforces评分达3206,位列人类选手排行榜第23名,LiveCodeBench Pass达93.5,IMOAnswerBench 得分89.8仅略逊于GPT-5.4,即便是轻量化的Flash-Max版本,Codeforces 评分也达到 3052,推理性能追平 GPT-5.2 等闭源模型。3、Agent能力:V4 Pro-Max任务解决率达80.6,与 Claude Opus 4.6基本持平,Terminal Bench 2.0、MCPAtlas Public等基准均处于开源模型第一梯队。4、长上下文能力:1M token场景下,MRCR、CorpusQA得分分别为 83.5、62.0,超越Gemini-3.1-Pro,且128K上下文内检索能力保持高度稳定。5、中文创作:其功能性写作对Gemini-3.1-Pro胜率达 62.7%,创意写作质量胜率高达77.5%,仅在高难度多轮约束场景略逊于Claude Opus 4.5。
三、模型技术架构:CSA+HCA+mHC进一步压缩推理成本1、首创CSA+HCA交替的混合注意力架构。通过分层KV缓存压缩与稀疏注意力结合,在1M token 上下文场景下,Pro 版本单token推理FLOPs仅为V3.2的 27%,KV缓存占用降至10%,Flash版本更是分别降至10%与7%,从底层解决了超长上下文的算力瓶颈;2、引入mHC流形约束超连接升级传统残差结构,提升了深层模型的信号传播稳定性与表达能力,同时采用Muon优化器搭配预期性路由、SwiGLU钳制技术,解决了万亿参数MoE模型训练的Loss Spike难题;3、采用领域专家独立训练+全词表在线蒸馏的后训练范式,规避了多能力融合的性能退化问题。
四、综合评价:依然是开源模型标杆,DeepSeek V4整体符合预期。DeepSeek V4整体表现来看,在百万上下文、国产化适配层面超出市场预期,但在多模态能力、复杂任务指令跟随上未达此前市场的高预期。1、行业此前普遍期待其在推理、代码能力上延续DeepSeek系列的优势,实现对前代模型的全面超越。而V4不仅达成了这一目标,更以原生1M token 上下文支持、万亿参数模型的国产芯片适配,实现了超预期突破,成为首个完成该级别国产化适配的顶级开源大模型,同时在实际工程测评中DeepSeek的表现令人满意。2、多模态能力并未随本次发布落地,与同期GPT-5.5、Claude Opus 4.7 等模型的多模态升级形成差距,让部分用户产生了心理落差。3、实际使用表现:中文创作能力实测表现优异,长文档生成与续写效果显著优于多数竞品;代码开发能力在内部真实R&D任务中通过率达 67%,远超 Claude Sonnet 4.5,接近Opus 4.5水平;同时具备极高的性价比,Flash版本定价仅1 元/2元每百万 token,Pro版本相较海外顶级闭源模型便宜约60%,且后续随昇腾 950产能释放存在进一步降价空间。
但实测中也暴露了部分短板:复杂Agent场景下对自定义工具的调用触发灵敏度不足,多约束条件的开发任务中存在未与用户确认便执行操作的问题,高难度多轮创意写作场景的表现仍落后于Claude Opus 4.5,通用复杂任务的鲁棒性仍有优化空间。
五、展望未来与投资建议DeepSeek V4是国产算力在国产通用大模型在训练侧从0到1的尝试。此前国产大模型采用国产算力均用于推理侧,而DeepSeek本次从模型内核到训练架构、到推理全流程均出现了国产算力的影子,属于从0到1的里程碑。因此,无论DeepSeek V4表现如何,性能意义都显得相对寡淡,对国产算力的训练适配前景才是关注的重点。我们期待未来继续让全世界听到DeepSeek的声音。
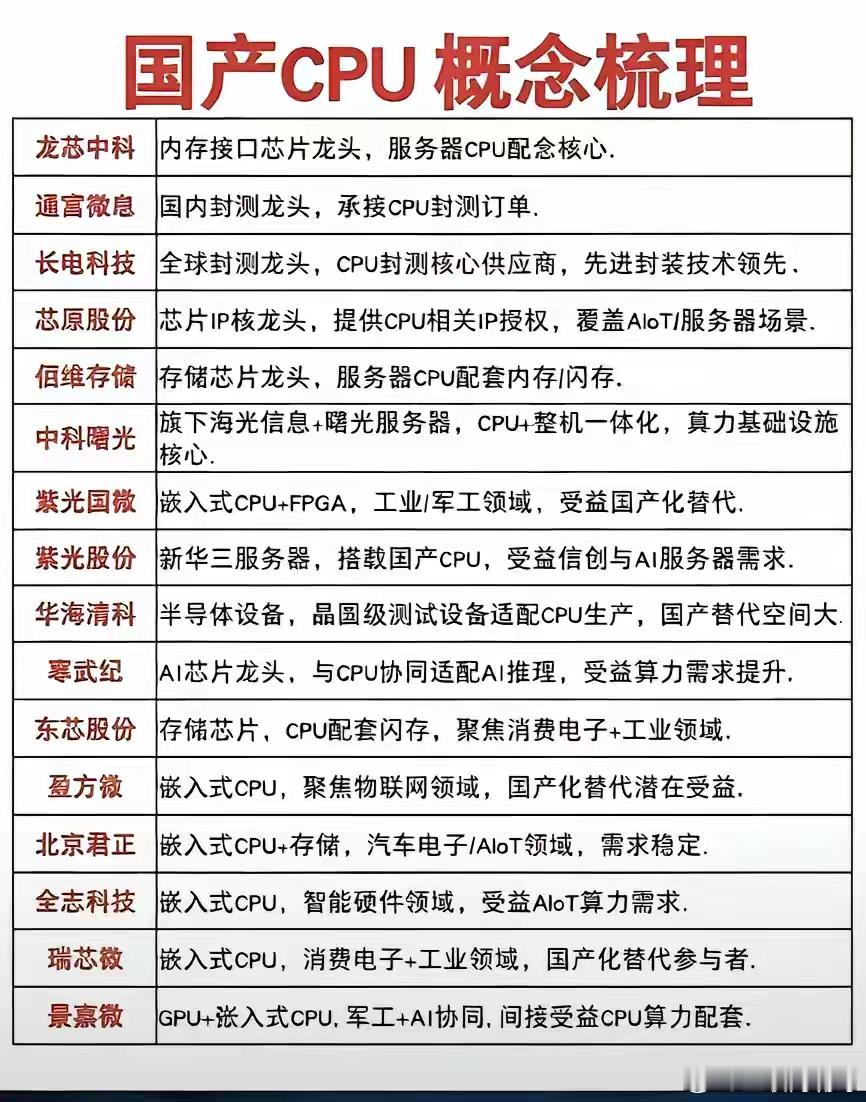
建议关注:国产算力崛起相关标的