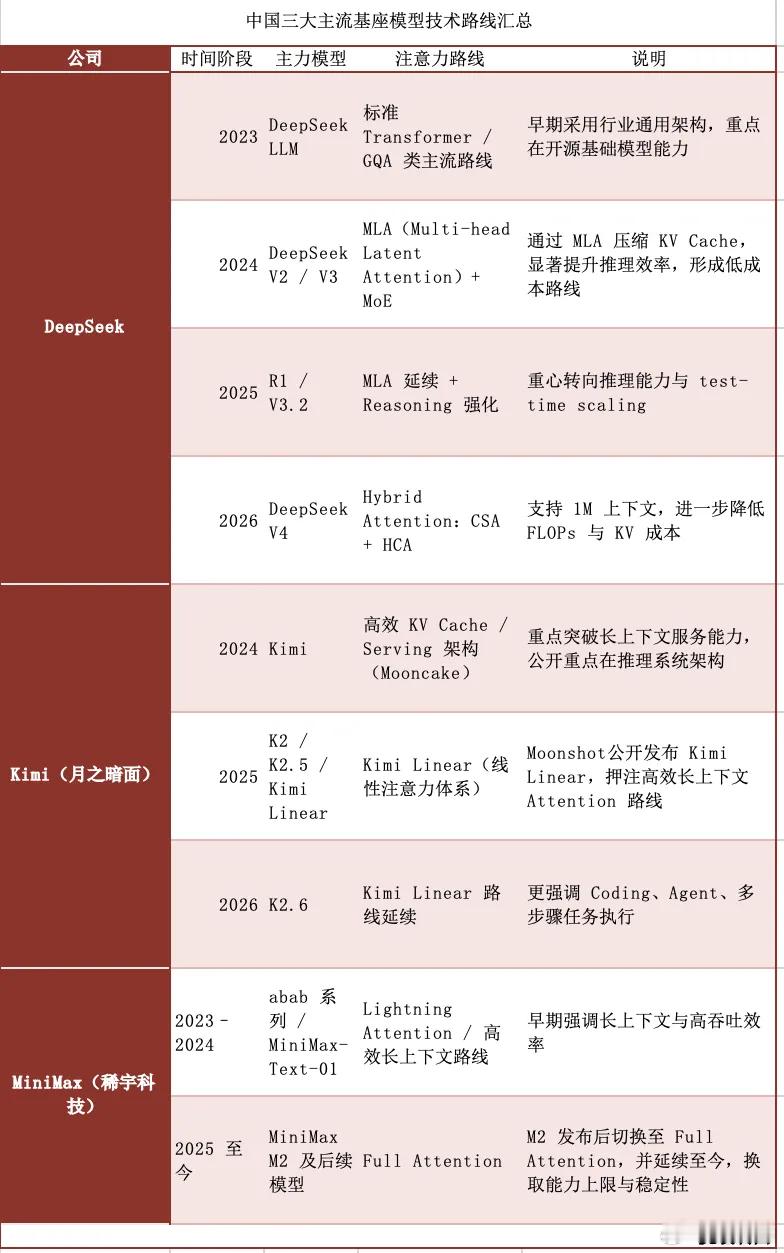
美封锁芯片必赢?DeepSeekV4横空出世,外媒慌了:中国AI走通新路 三年前,美国挥出芯片封锁的“大棒”时,舆论几乎一边倒地认为结局已注定:少了顶级GPU、先进制程和海外算力,中国AI只能被迫减速,甚至停滞。 可现实的发展往往比预测更出人意料。最近,DeepSeek发布V4模型,外媒在惊叹其性能提升的同时,更关心一个隐藏信号——中国人工智能正在以不同于传统赛道的方式快速前进。 过去,大家常用“参数规模”“算力多少”去衡量一个模型的竞争力。而DeepSeek的节奏却明显不一样。它的关注点从“堆参数”转向“算得更精、更高效、更能落地”。 这类转变,其实反映了国产大模型发展的新阶段:不只是追赶,更是尝试建立属于自己的技术逻辑。 斯坦福大学今年的《AI Index》报告指出,中美顶级模型性能差距已经明显缩小。从前,差距是“代际”级;如今,越来越多指标仅是“水平差”。 这意味着,外部的技术封锁未能阻止中国AI的成长曲线,反而促成了技术路线的多样化——尤其在工程层和系统设计层。 DeepSeek的策略成了一个典型样本。它不再依赖于高端GPU的大显存和带宽优势,而是通过优化模型结构、精细化的KV Cache调度、内存共享机制和多层推理架构,来突破显存瓶颈。这样一来,模型运行的门槛明显降低,部署成本下降,可覆盖的应用场景随之扩大。 这背后其实是一种战略思维的转变。过去的逻辑是:算力=芯片数量;而现在的逻辑变成:算力=算法效率×系统协同。 DeepSeek V4正好揭示了这一转折——谁能在工程优化层突破“显存墙”,谁就能让大模型在普通硬件上跑得更稳、更快。 更值得注意的是,这条路线并不孤单。华为昇腾等国产算力平台正在和各主流国产模型逐步打通接口,实现更深层的兼容。这意味着从模型、芯片到云平台的闭环正在形成。 中国AI产业不再只是一系列独立的“点”,而在变成能自我循环、自我强化的生态系统。 对外界而言,这种变化的意义不只是一个模型升级,更像是一次系统性路径验证。它说明:顶级AI竞争不再由单一硬件主宰,而是进入综合实力的比拼——模型能效、软件架构、产业协同、应用能力,全部纳入竞争范畴。 随着DeepSeek V4的问世,芯片封锁的效果正在被现实稀释。限制虽未解除,但产业正在用工程智慧找出新路。 当一个生态能够独立完成从算力到模型再到落地的闭环,就意味着它不再依附单一供应链。未来几年,“硬件焦虑”可能会被“系统自信”取代。 这场竞争,显然已经进入新的阶段。