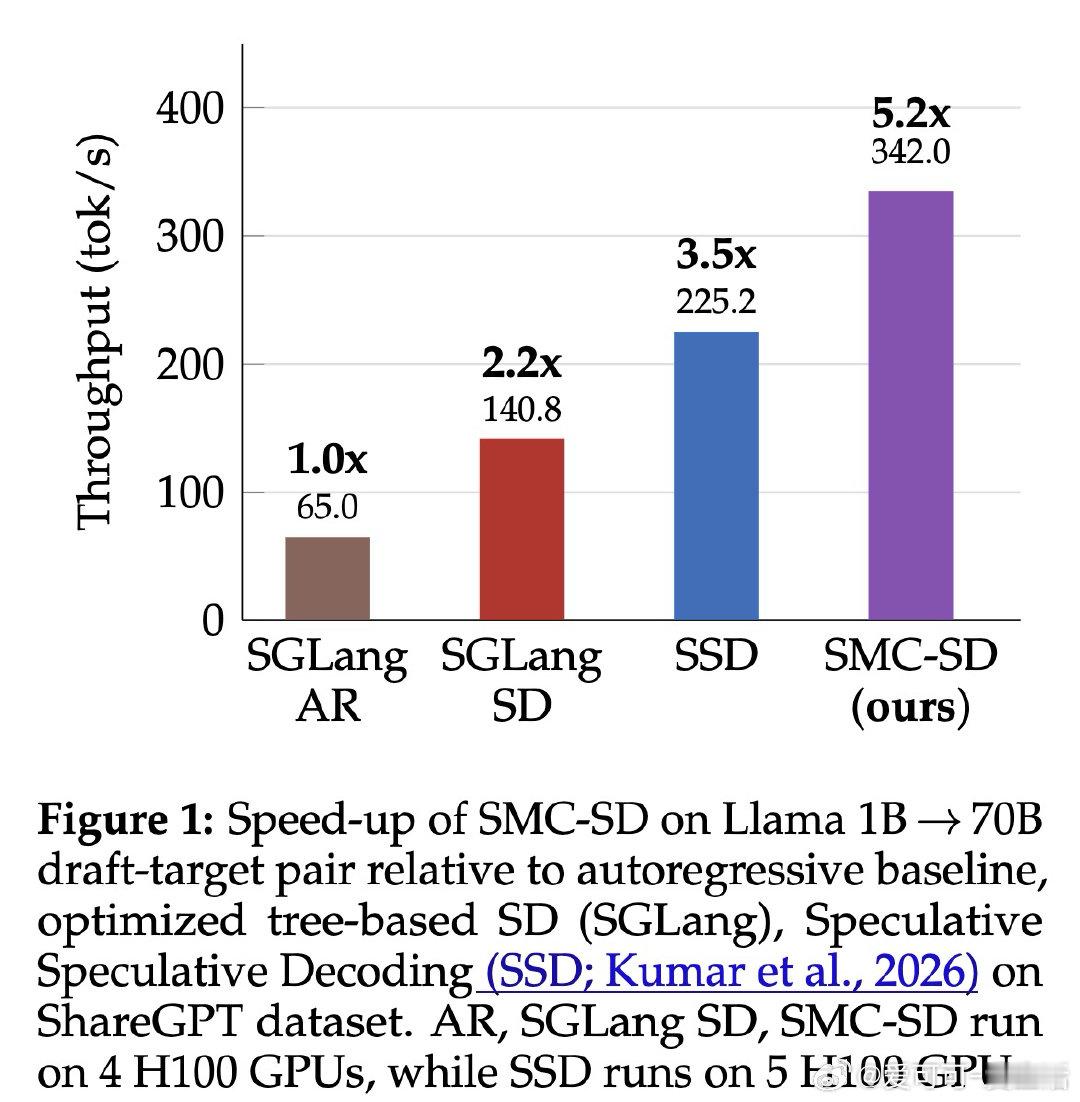
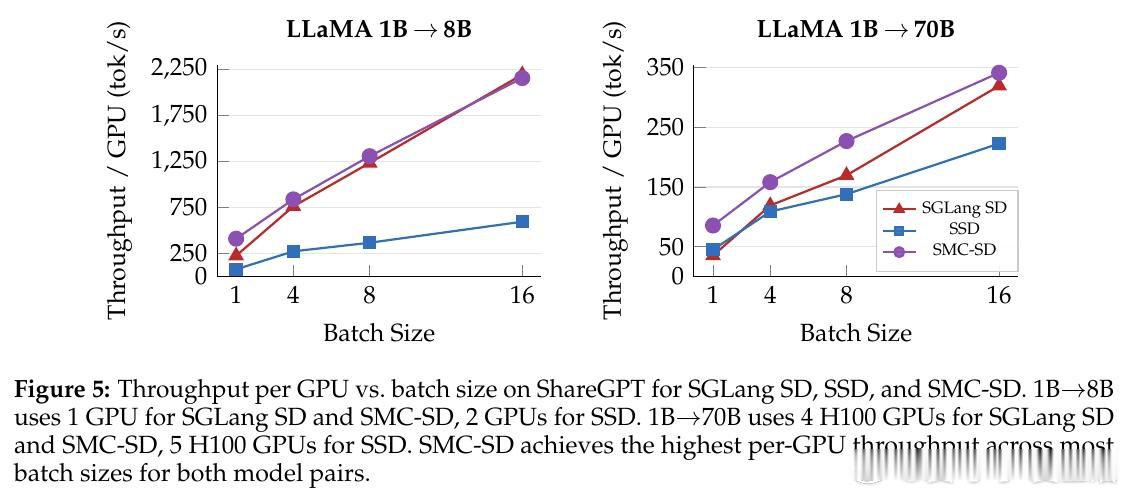
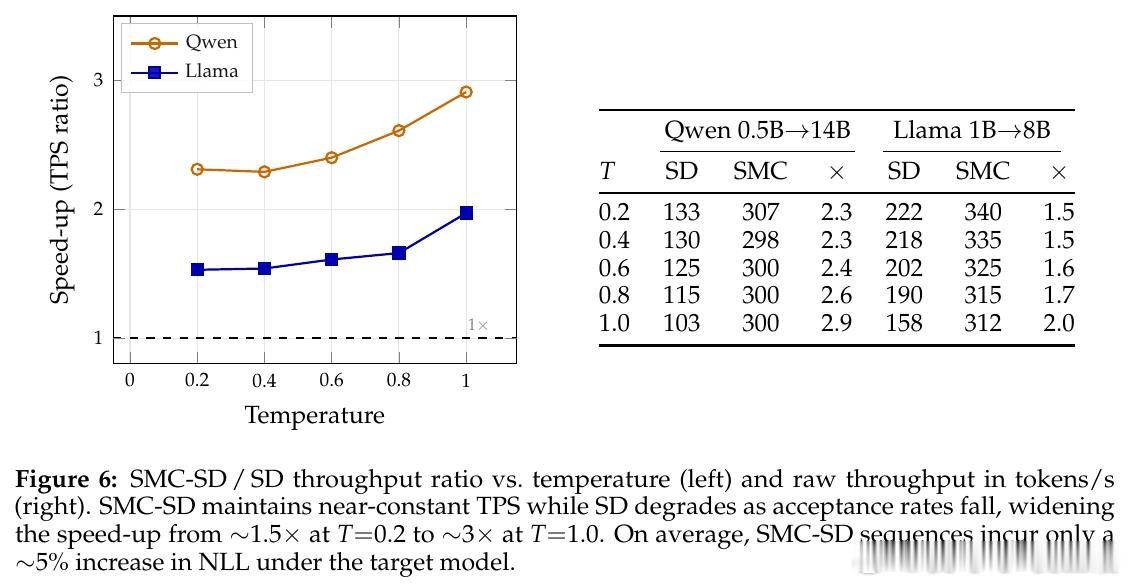
[LG]《Faster LLM Inference via Sequential Monte Carlo》Y Emara, M B d Costa, C Chang, C Freer… [Cornell University & MIT] (2026)
在大语言模型推理领域,每生成一个词元都需要独立调用庞大目标模型,成为吞吐量的根本瓶颈。现有的推测解码通过小模型起草、大模型验证来摊薄成本,但一旦起草质量下滑,拒绝机制会截断草稿序列,速度增益随之崩塌。
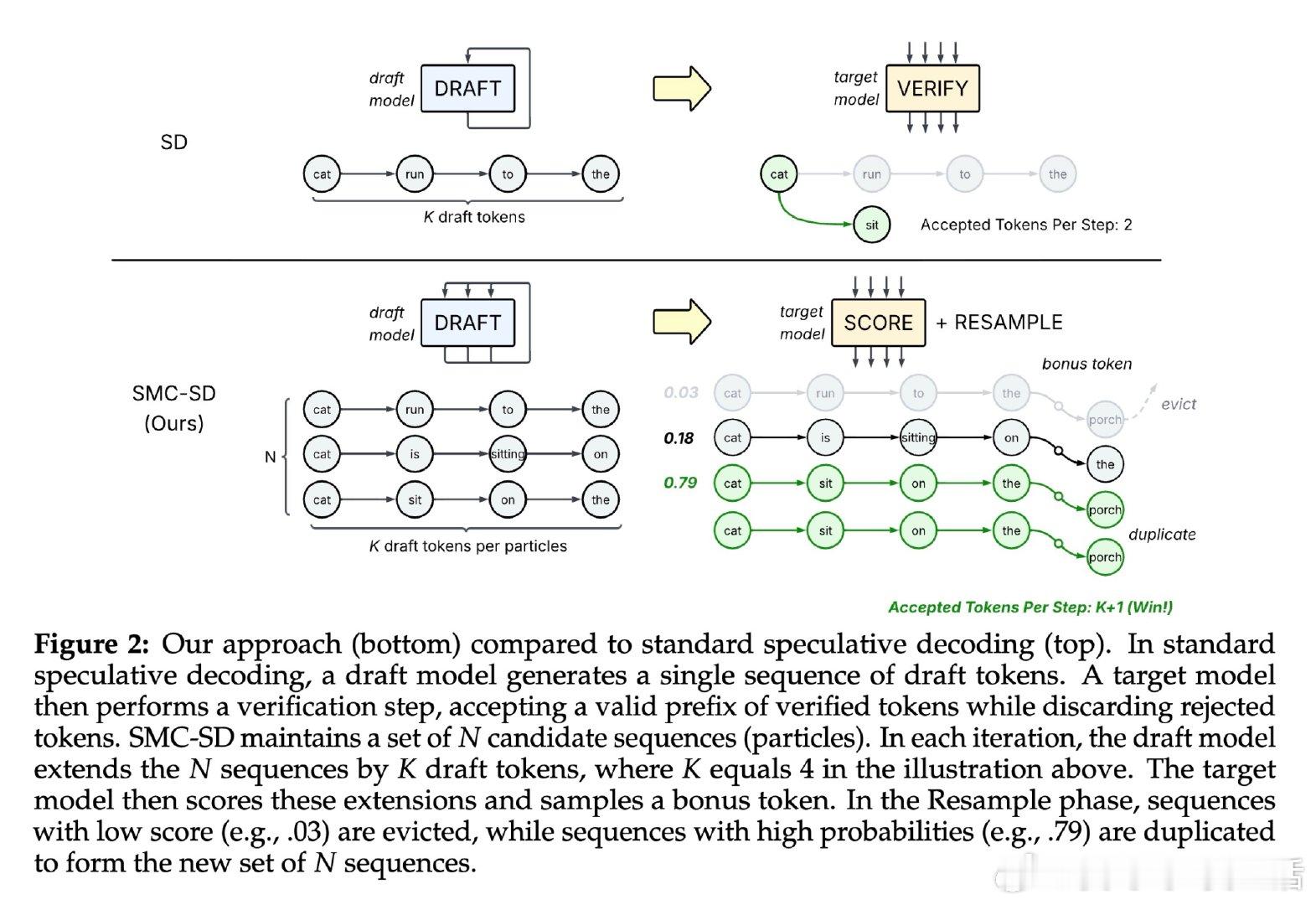
本文的核心洞见是:把"逐词验证"重新看作"粒子种群的重要性重采样"。由此,用连续权重替代二元接受/拒绝这一关键操作使问题得以解开——每个粒子不再被截断,而是按与目标分布的吻合度获得权重,低权重粒子被淘汰,高权重粒子被复制,固定数量的词元稳定输出。
这项工作真正留下的遗产是:将序列蒙特卡洛这一统计推断框架与GPU硬件的并行计算结构深度绑定,使"近似推理换取吞吐量"成为可调的工程旋钮。它为后来者打开的新门是:同一套粒子重加权机制可扩展至奖励引导解码、约束生成等无归一化常数的分布采样场景;但尚未跨过的门槛是:多轮重采样导致的粒子路径退化误差目前仍缺乏端到端的理论界定。
arxiv.org/abs/2604.15672
机器学习 人工智能 论文 AI创造营