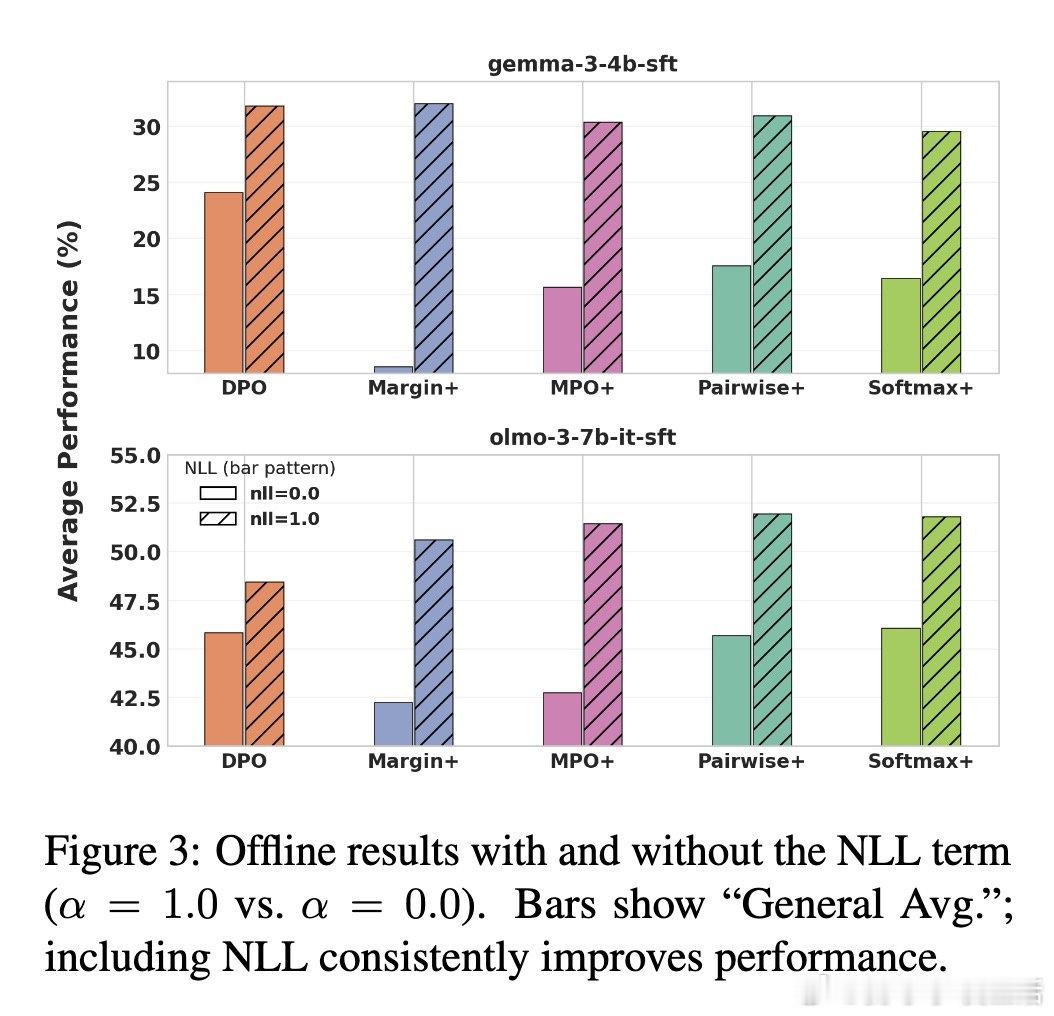
[CL]《GroupDPO: Memory efficient Group-wise Direct Preference Optimization》J Leng, S Si, H Yu, V Raman… [CMU & Google Deepmind & Google] (2026)
在大语言模型对齐领域,如何从偏好数据中榨取更多监督信号,是一个悬而未决的工程难题。过去的方法将多候选回答强行压缩为单一正负对,本质是在用一把信息以换取计算上的便利,而随着群组规模增大,显存占用呈指数级爆炸,使得这一压缩几乎成为不得不做的取舍。
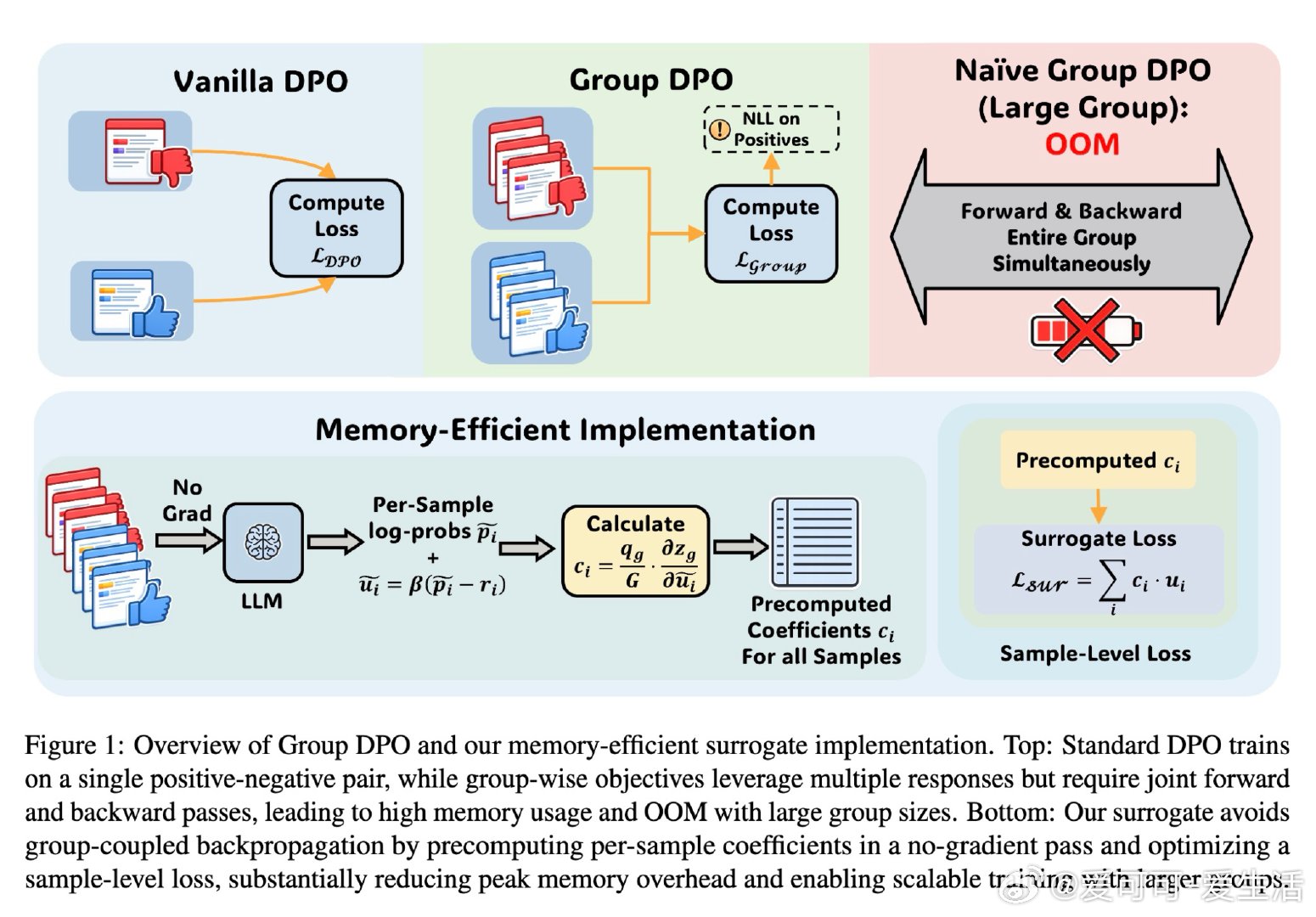
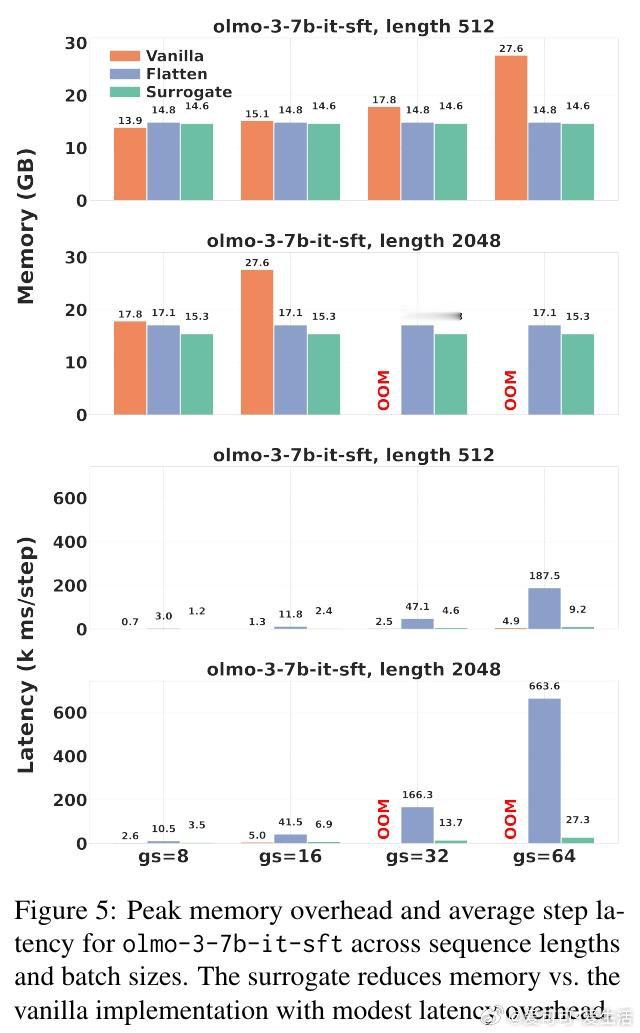
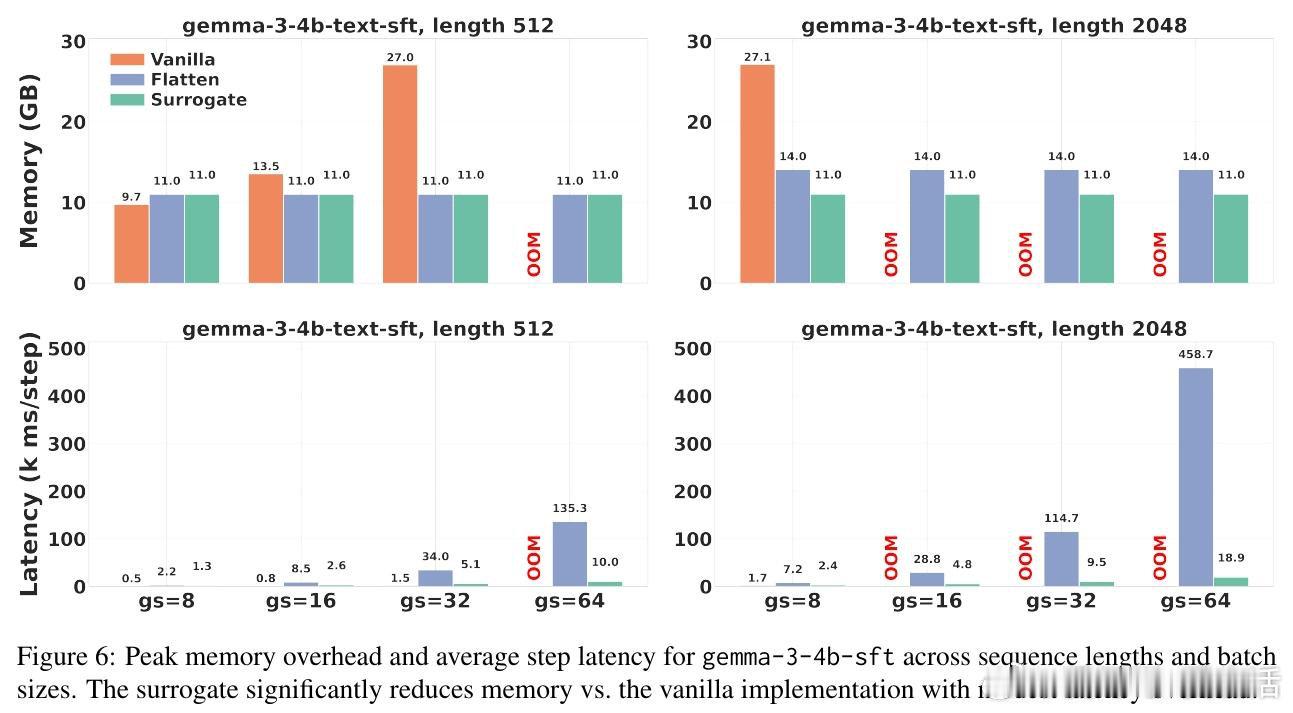
本文的核心洞见是:把群组目标的反向传播重新看作一个系数预计算问题。由此,先用无梯度前向传递算出每个样本对群组损失的贡献权重,再以这些权重驱动标准的逐样本反向传播——这一关键操作将显存复杂度从与群组大小强耦合,解耦为近似常数,使大群组训练成为可能。
这项工作真正留下的遗产是:证明了群组偏好优化在效果与效率上可以同时成立,而非二选一。它为后来者打开的新门是:借助这一代理实现,更大的群组、更复杂的排序目标将不再受限于硬件天花板,为后训练阶段注入更密集的比较信号。但尚未跨过的门槛是:当前代理目标是原始损失的一阶线性化,对依赖二阶曲率的优化器行为尚无理论保证,且额外的无梯度前向传递在延迟敏感场景下仍是一笔不可忽视的开销。
arxiv.org/abs/2604.15602
机器学习 人工智能 论文 AI创造营