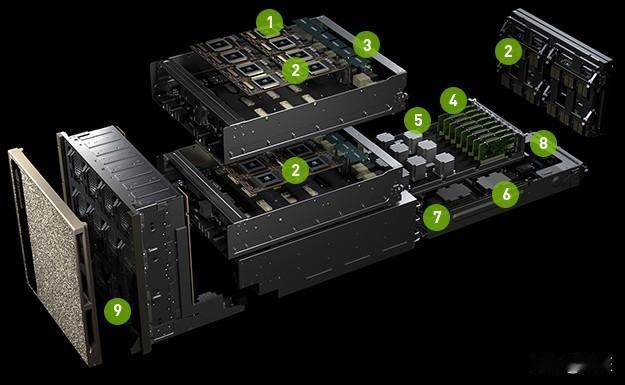
英伟达正在为“实时AI推理时代”奠定基础。据最新爆料消息,NVIDIA计划在下一代费曼(Feynman)架构的GPU中,引入源自格罗格(Groq)公司的语言处理单元(LPU),并搭配X3D堆叠设计,这将使AI推理速度实现质的飞跃。这意味着NVIDIA不再仅仅聚焦于AI训练领域,而是开始积极应对语音助理、实时翻译、实时响应等低延迟应用的市场需求。 核心在于制程和堆叠策略发生了改变。费曼架构预计会采用台积电的A16(1.6纳米)制程技术,同时结合系统整合芯片(SoIC)混合键合技术,把专门为推理设计的LPU单元直接堆叠在GPU之上。这种做法乍一看和AMD的3D V - Cache技术有些相似,但二者存在明显区别:NVIDIA堆叠的并非缓存,而是带有大量静态随机存取存储器(SRAM)、具备“确定性执行”特性的推理加速单元,以此来突破先进制程下SRAM面积和成本失控的瓶颈。 倘若这项设计能够取得成功,NVIDIA的GPU在实时AI场景中的反应速度和功耗效率,将迎来的不只是细微的提升,而是结构性的变革。然而,挑战也十分严峻:在高密度的GPU上再增加一层芯片,散热问题将成为一大难题;此外,LPU对内存配置和执行顺序有着极高要求,这可能会与CUDA长期依赖的硬件抽象化设计产生冲突。这场“豪赌”,考验的不仅仅是制程和封装技术,更是NVIDIA能否让硬件创新顺利融入现有的软件生态系统。