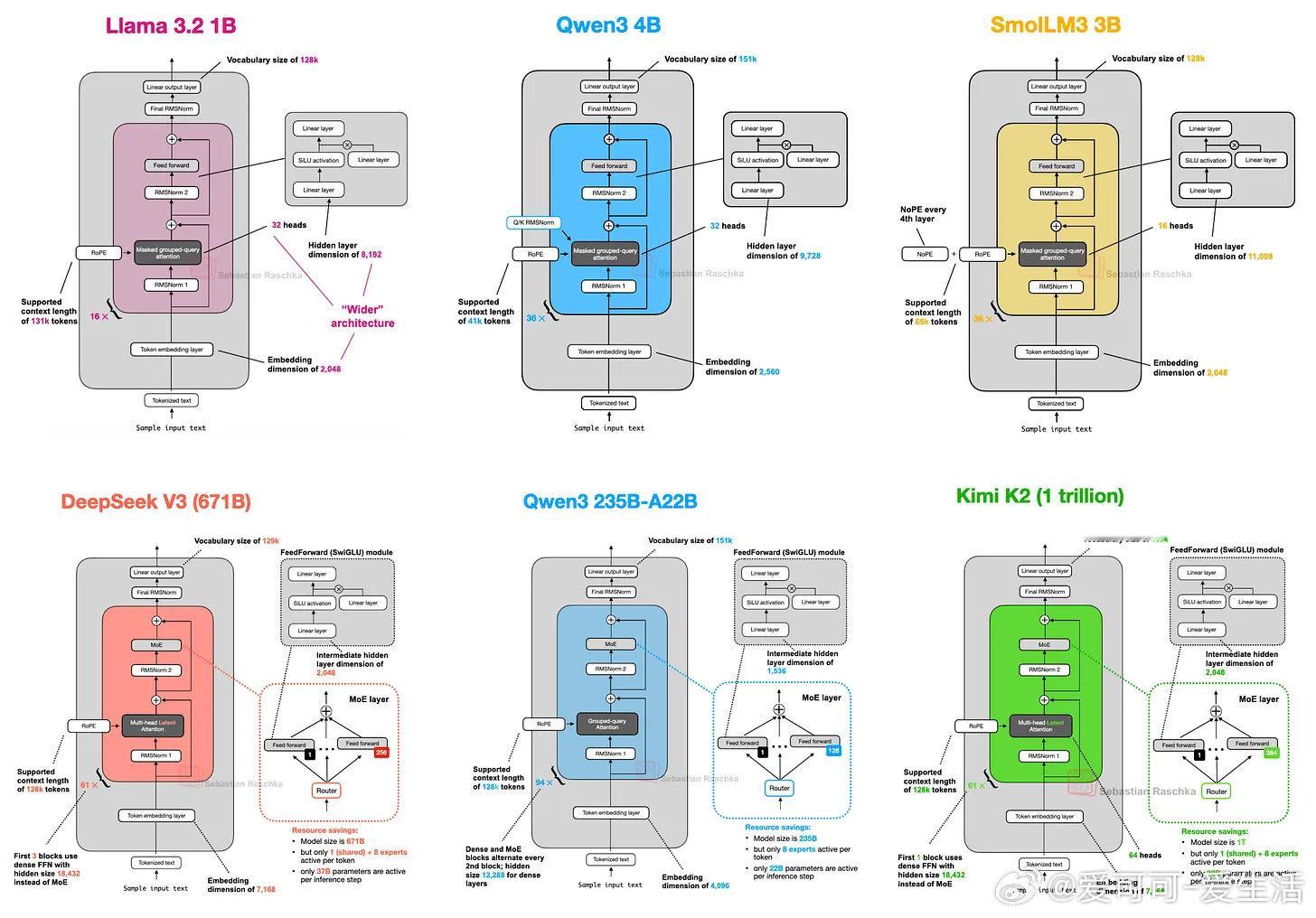
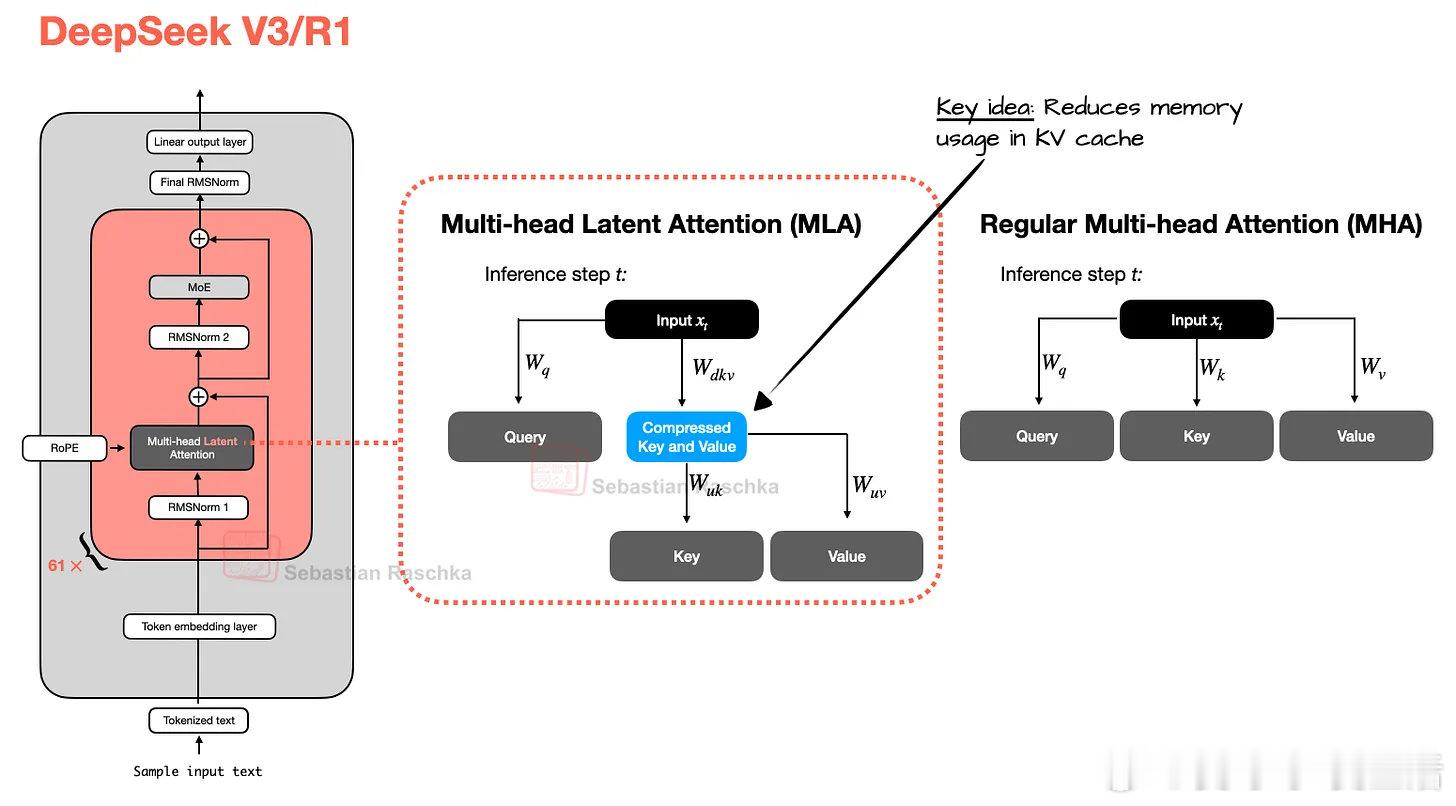
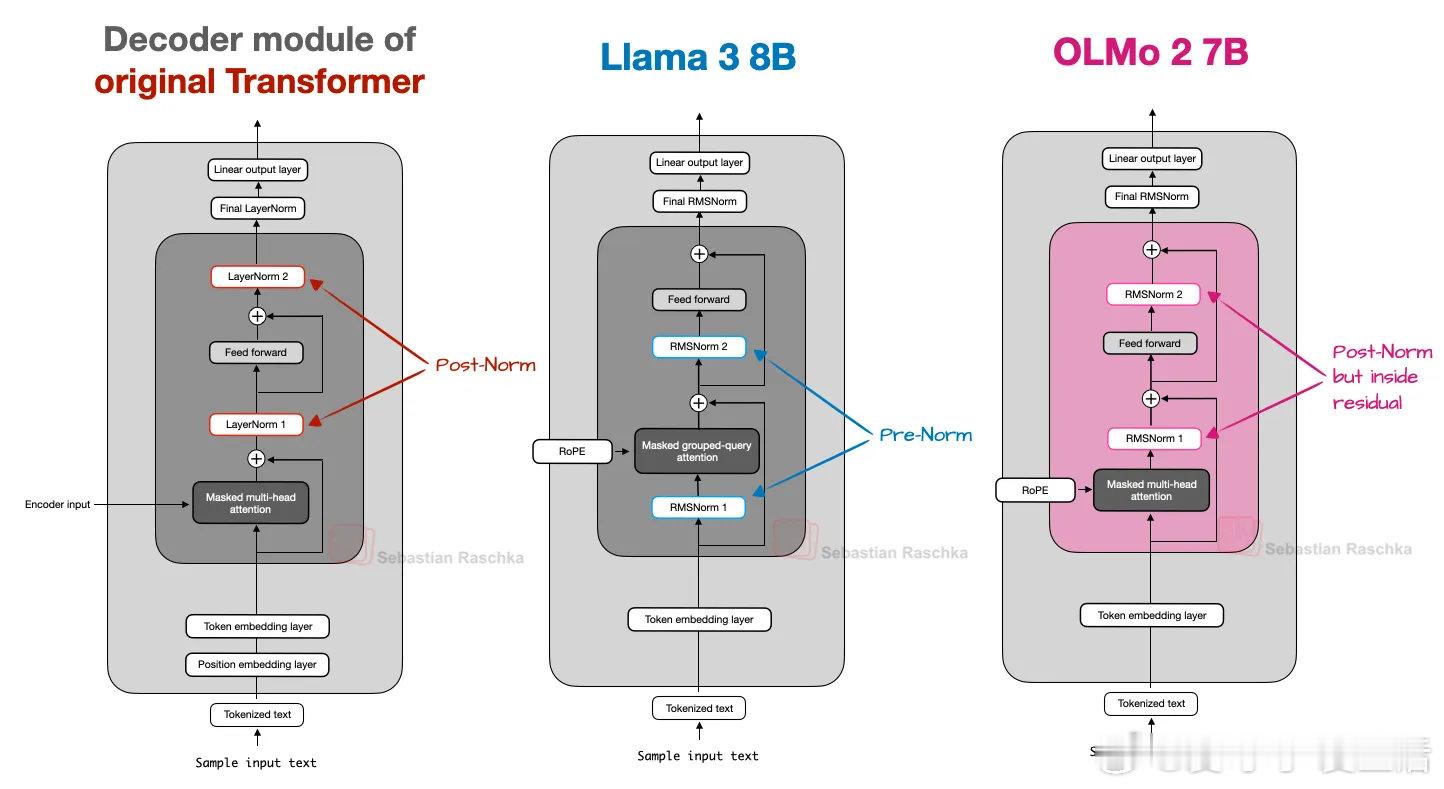
《The Big LLM Architecture Comparison》七年来,GPT架构演进虽有细节改进,但核心仍相似。从GPT-2到近期的DeepSeek V3与Llama 4,模型结构变化有限,更多是细节上的优化,如从绝对位置编码到旋转位置编码(RoPE)、多头注意力向分组查询注意力(GQA)转变,以及激活函数由GELU进化为更高效的SwiGLU。DeepSeek V3(2024末发布)及其推理版本DeepSeek R1(2025年初)引入了两大关键架构创新:多头潜在注意力(MLA)和专家混合(MoE)层。MLA通过压缩键值张量显著节省KV缓存内存,并在性能上超越GQA。MoE则通过稀疏激活少量专家,极大提升模型容量与推理效率,DeepSeek V3拥有6710亿参数,但推理时仅激活37亿,大幅降低推理资源消耗。非盈利Allen AI的OLMo系列以高透明度著称,虽非性能最强,但其对训练数据和代码的公开为社区提供了宝贵的蓝图。OLMo 2采用Post-Norm(归一化层置于注意力与前馈模块之后)搭配QK-Norm(针对查询和键的归一化),提升训练稳定性,区别于主流的Pre-Norm设计。谷歌的Gemma系列(尤其是Gemma 3)强调滑动窗口注意力机制,限制每个查询的上下文范围,大幅降低KV缓存内存,用局部注意力替代全局注意力,保持性能几乎不变。Gemma 3还采用了Pre-Norm与Post-Norm混合归一化,兼顾训练稳定性与效率。此外,Gemma 3n针对移动设备进行了优化,利用分层嵌入(PLE)技术降低内存占用,并引入了Matryoshka Transformer结构,实现模型切片灵活部署。Mistral Small 3.1以较小KV缓存和更少层数提升推理速度,虽舍弃滑动窗口注意力,但性能在多场景优于Gemma 3,凸显宽模型在推理速度上的优势。Llama 4 Maverick采用MoE架构但激活专家更少且规模更大,整体与DeepSeek V3类似,体现MoE在2025年的流行趋势。Qwen3系模型涵盖从0.6B到235B参数的密集和MoE版本,兼顾易用性和推理效率。其小型模型适合本地运行,MoE版本激活参数比例低,提升大规模应用的推理性价比。Qwen3 Next在较小规模下引入更多专家和共享专家,并采用混合门控DeltaNet注意力,实现超长上下文支持(262k tokens)和多步预测,提升训练速度和推理效率。SmolLM3以3B参数提供优异性能,采用NoPE(无显式位置编码)策略,增强对长序列的泛化能力,减少对位置编码的依赖。Kimi K2体量达到1万亿参数,基于DeepSeek V3架构扩展,采用Muon优化器替代AdamW,训练损失曲线平滑且下降迅速,性能媲美领先私有模型。最新的Thinking版本将上下文扩展至256k tokens,提升推理能力。OpenAI最新开源的gpt-oss系列(20B和120B)采用类似Qwen3的MoE设计,结合滑动窗口注意力和注意力偏置,架构更宽而较浅,适合高吞吐量推理。其“注意力汇聚”机制(attention sinks)通过头偏置实现长上下文稳定性。xAI的Grok 2.5作为去年旗舰模型,采用少量大专家,并引入始终激活的共享专家模块,与近期多专家模型设计呼应。GLM-4.5通过先密集后稀疏的层序设计提高MoE模型稳定性,性能优于Claude 4 Opus,接近OpenAI和xAI的顶尖水平。MiniMax-M2在保持高性能的同时回归全注意力,摒弃线性注意力的准确性不足问题,采用每层独立QK-Norm,参数激活比例更低,体现稀疏MoE架构的新趋势。2025年线性注意力迎来复兴,Qwen3-Next和Kimi Linear将轻量级线性注意力与传统全注意力混合,兼顾效率与性能。Kimi Linear通过通道级门控提升长上下文推理能力,在速度和准确性之间取得平衡。Allen AI最新的Olmo 3在保持透明度的基础上扩展规模,继续采用Post-Norm和滑动窗口注意力,支持64k上下文,表现稳定。DeepSeek V3.2引入稀疏注意力机制,与Mistral 3大型MoE模型架构相似,后者增加视觉编码器支持多模态,优化推理速度,体现MoE架构的持续进化。综观2025年旗舰开源大模型,核心仍是Transformer,但细节创新如多头潜在注意力、Mixture-of-Experts、滑动窗口与线性注意力混合、归一化层位置变换等,推动模型在性能和推理效率间取得更优平衡。MoE架构热度持续攀升,模型规模与激活参数数目被巧妙控制,实现大规模知识整合与高效推理。长上下文支持成为新标准,优化训练稳定性和推理速度的技术层出不穷。未来,架构创新与训练工艺的协同将持续塑造大语言模型的发展路径,开源社区的透明度和多样化探索为行业注入活力。magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison