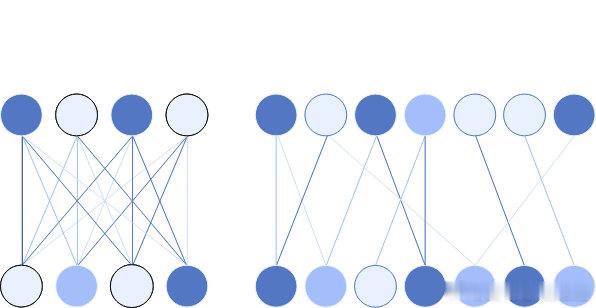
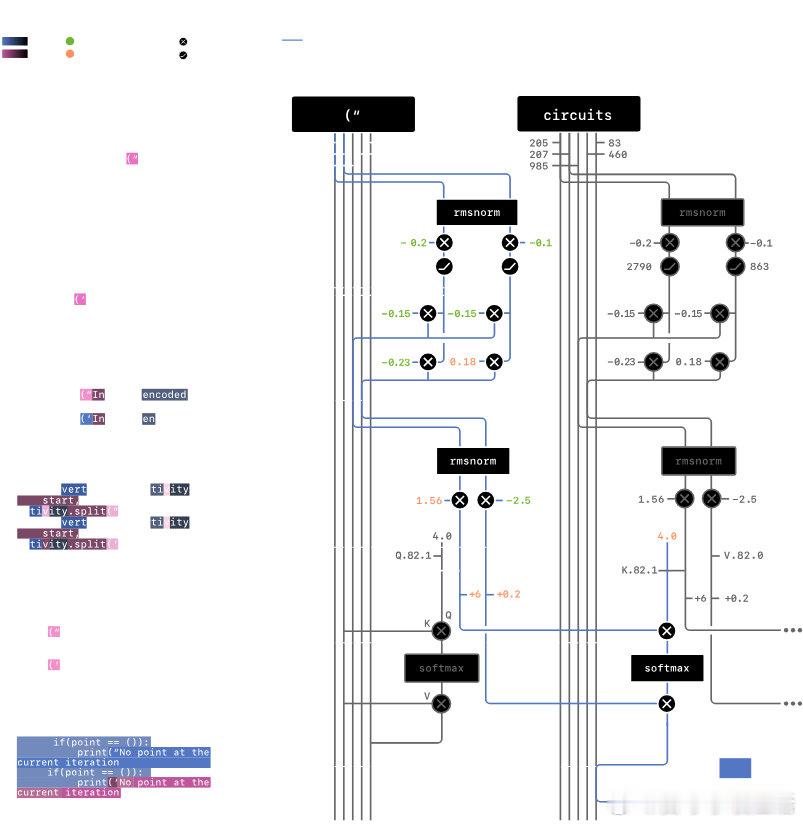
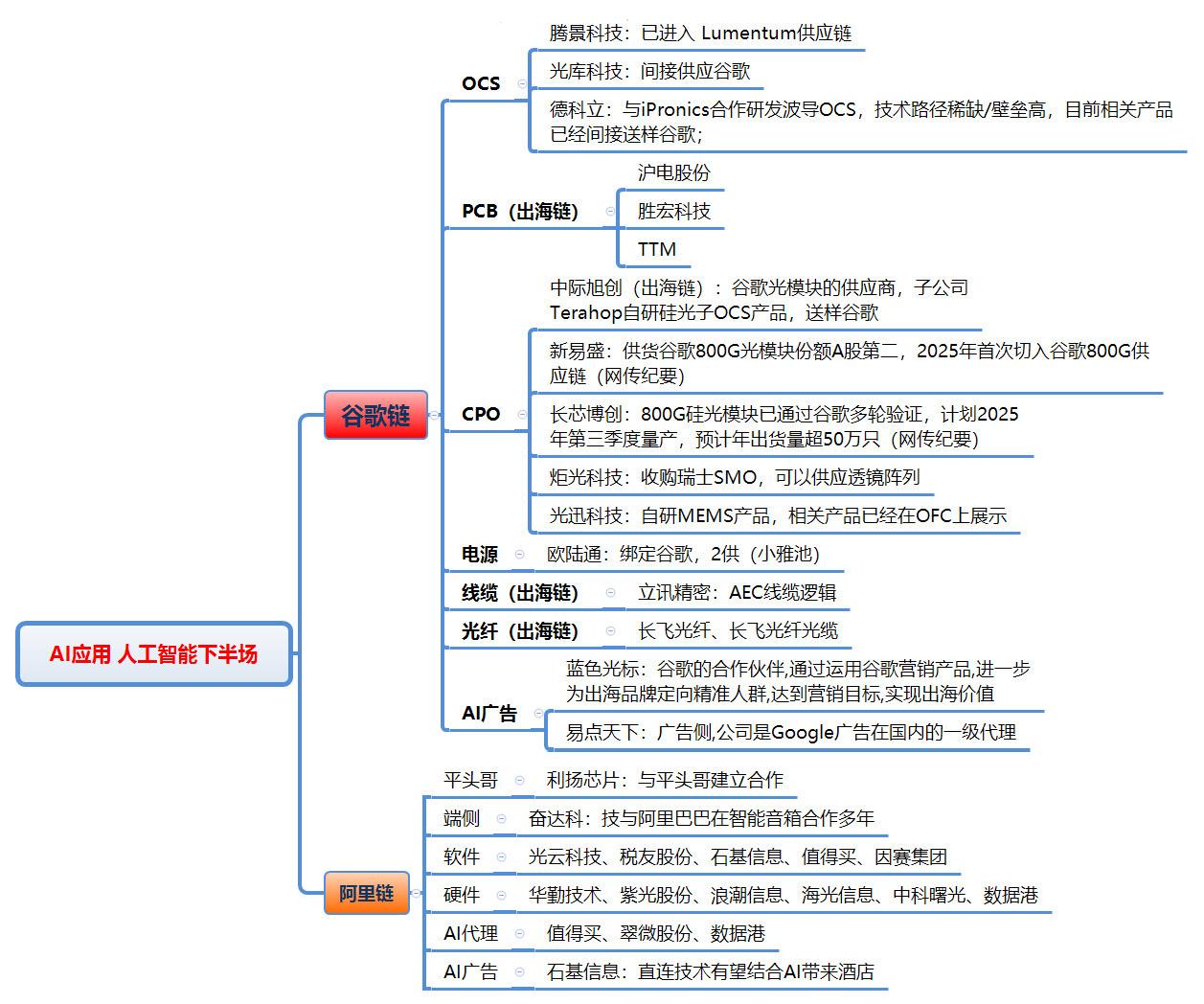
《通过稀疏回路来理解神经网络》神经网络驱动着最强大的人工智能,但其复杂的密集连接让人难以理解。可解释性对于在科学、教育和医疗等关键领域安全应用AI至关重要。当前,推理模型通过链式思维提供部分解释,便于监控和识别异常行为,但依赖这种方式存在脆弱性。OpenAI团队提出,机理可解释性通过逆向工程模型计算,能更全面地揭示其内部机制,虽挑战巨大,但有望提升对模型行为的信心和安全预警能力。更重要的是,他们发现训练“稀疏神经网络”——即神经元间连接大幅减少的模型——能显著简化内部结构,使得关键行为对应的小型电路更易于识别和理解。具体来说,稀疏模型将绝大多数权重置零,每个神经元只连接少数节点,促成了清晰、可分离的计算回路。例如,在一个字符串闭合引号识别任务中,模型内部形成了仅由少数神经元和注意力通道组成的回路,精准执行匹配操作,且这些回路既必要又充分。更复杂任务中,回路虽更难完全解读,但仍能提供有价值的行为预测。这表明存在一条可行路径:通过设计和训练稀疏模型,未来有望构建既强大又可解释的AI系统,推动AI安全与透明发展。下一步,团队计划扩展方法到更大规模模型,并探索从密集模型提取稀疏电路或开发高效训练技术,以提升实际应用潜力。尽管还远未达到完全理解强大模型的理想,但这项工作为解开AI黑箱提供了重要思路,助力构建更安全可靠的智能系统。openai.com/zh-Hans-CN/index/understanding-neural-networks-through-sparse-circuits/