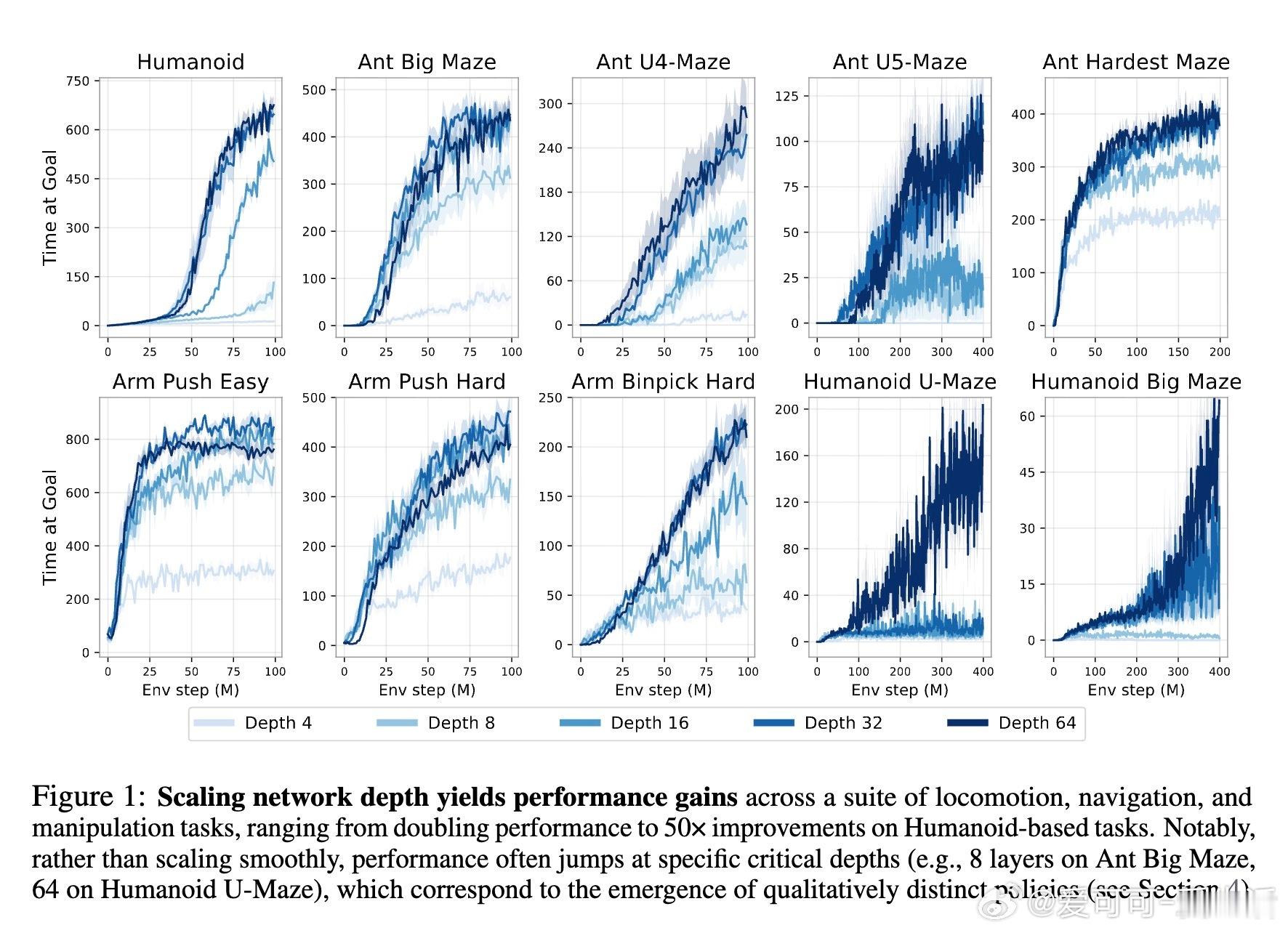
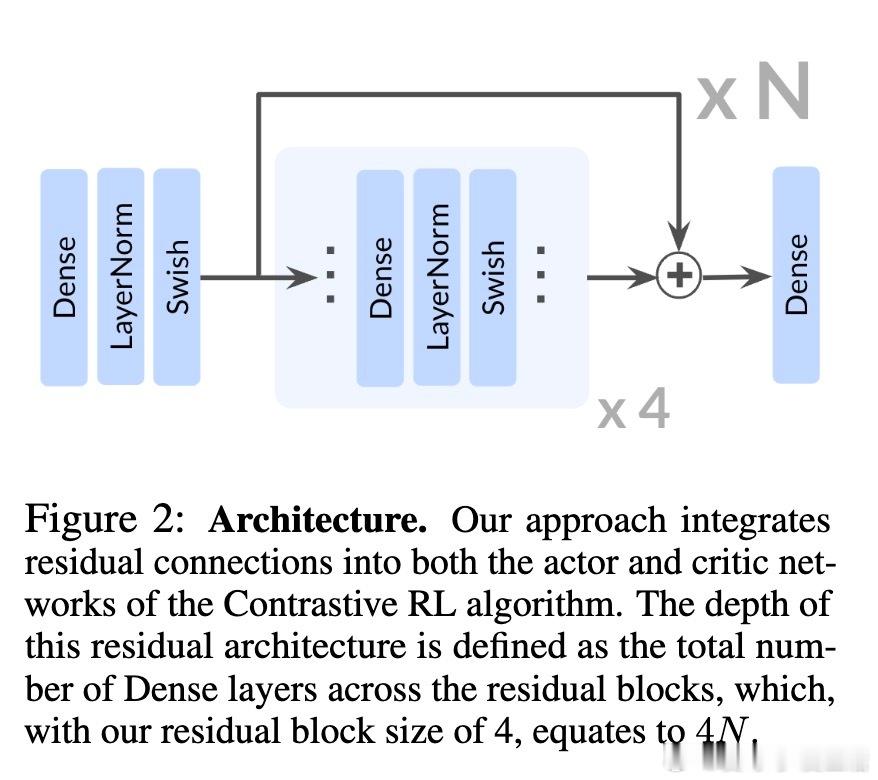
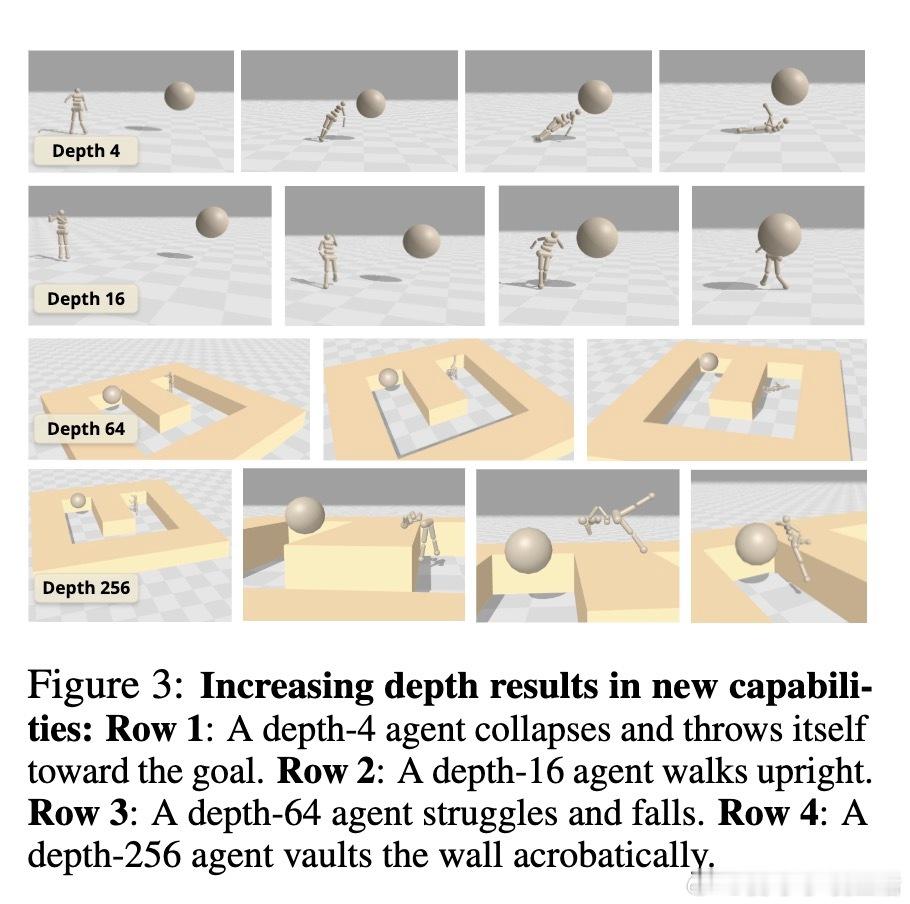
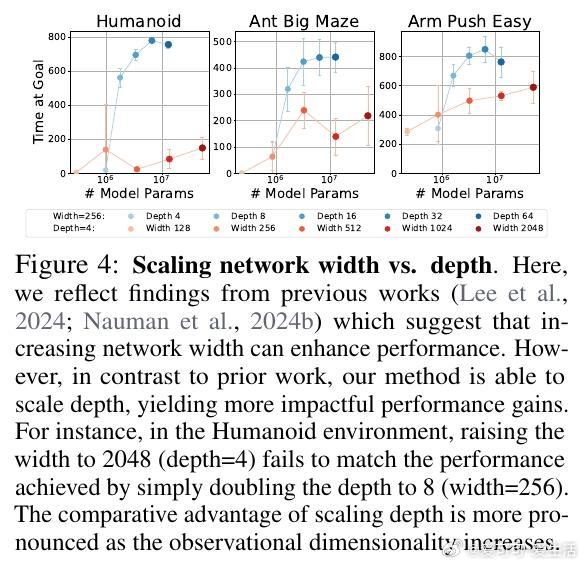
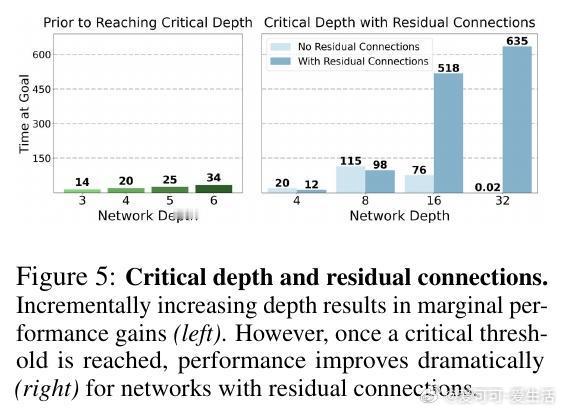
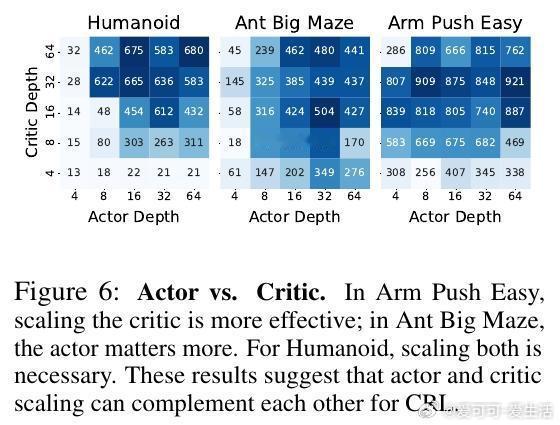
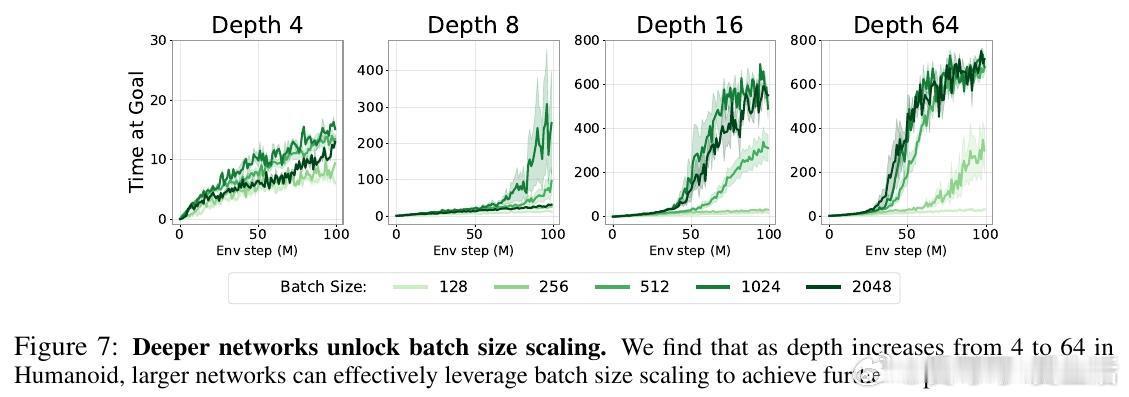
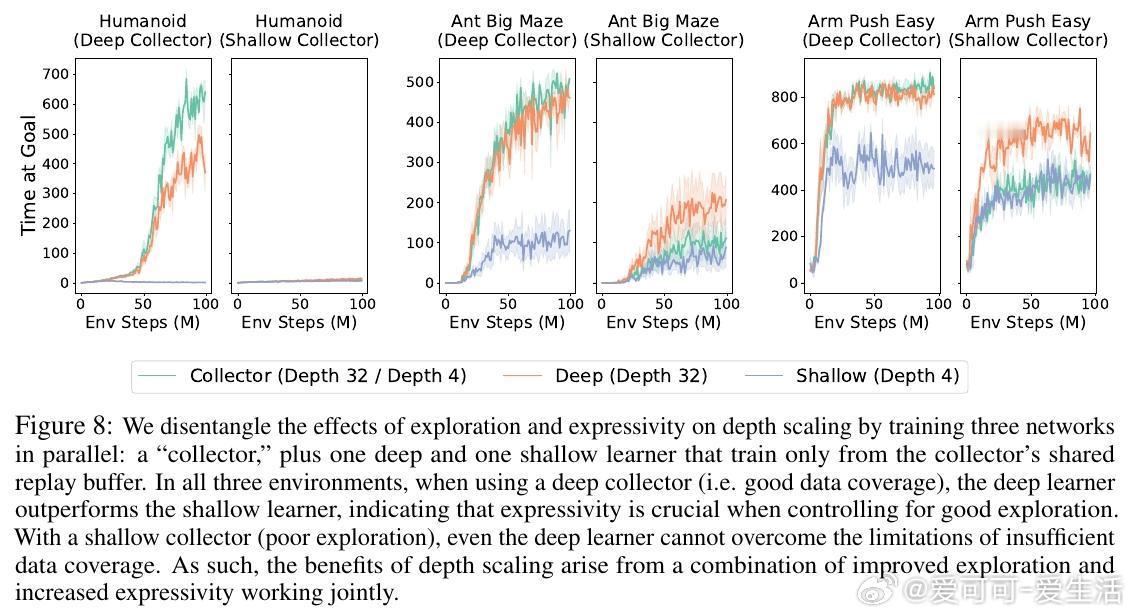
[LG]《1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities》K Wang, I Javali, M Bortkiewicz, T Trzcinski... [Princeton University] (2025) 在强化学习(RL)领域,模型规模的提升一直未能像语言和视觉领域那样带来突破性进展。最新研究提出,网络深度是关键因素。与传统RL多用2-5层浅层网络不同,本文实验中深度扩展至1024层的对比强化学习(Contrastive RL)算法,性能提升可达2到50倍,尤其在复杂的人形机器人和迷宫导航任务中表现卓越。研究基于无监督的目标条件强化学习,智能体无需示范或奖励,完全自探索以最大化达成指定目标的概率。深度扩展不仅提升成功率,还带来了质的飞跃:浅层网络常出现倒地或简单投掷运动,深层网络则能实现直立行走、跨越障碍甚至翻越墙壁等复杂行为,显示出“临界深度”现象——在特定层数后,策略能力突然跃升。此外,深度扩展助力扩大批量训练规模,解锁更强的表达能力和探索能力协同提升。通过设计“采集者-学习者”实验,研究发现深网络既能采集更丰富数据,也能更有效利用这些数据,表现出更优策略。深度网络还能更精准地分配表示容量,对关键状态(如靠近目标)进行细致区分,增强泛化能力,甚至实现任务经验的组合拼接(partial experience stitching)。与传统依赖宽度扩展的工作不同,该方法证明深度扩展在计算效率和性能提升上更具优势。例如,在人形机器人任务中,4层宽度2048的网络参数比32层宽度256的模型多10倍以上,但后者表现更优。研究还发现,深度扩展对于Actor和Critic网络均有益,二者配合可最大化性能。该方法的成功关键在于结合残差连接、层归一化和Swish激活函数等架构设计,保证深层网络训练稳定。值得注意的是,深度扩展在离线强化学习中效果有限,提示未来工作需探索适配策略。此外,深层网络训练成本较高,未来可通过分布式训练、剪枝与蒸馏等手段优化。总的来说,这项研究为RL领域带来了一个重要启示:深度是提升自监督强化学习规模化能力的核心维度,深层网络能够自主发现并掌握复杂技能,推动RL从浅层模型向大规模智能系统迈进,开辟了训练自主探索和学习能力更强智能体的新路径。论文链接:wang-kevin3290.github.io/scaling-crl/ 论文预印本:openreview.net/forum?id=s0JVsx3bx1深度带来的不仅是参数量的增加,更是智能体能力的质变。正如语言和视觉领域的经验所示,突破“临界规模”才能激发真正的智能。强化学习也正站在这一门槛上,深度扩展或将成为开启下一代自主智能的钥匙。