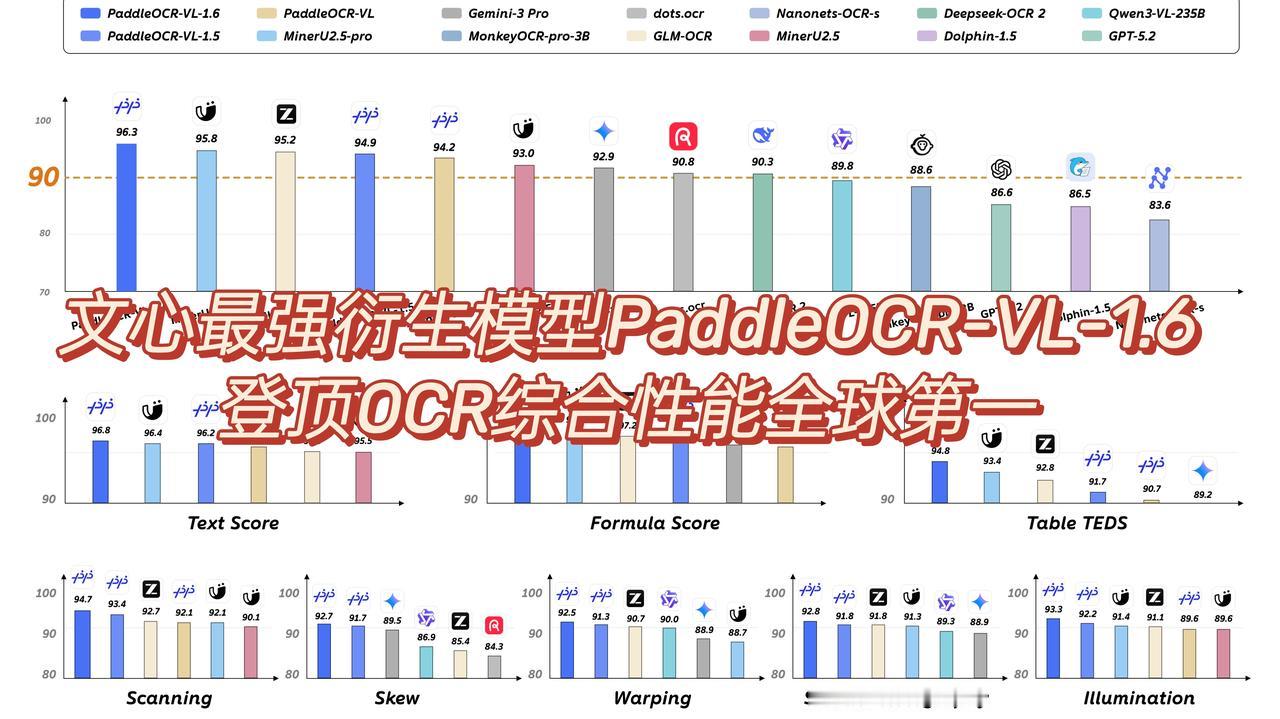
【AI内卷白热化,为何巨头纷纷疯狂抢实体书?】 不知道大家有没有发现,现在的AI卷得越来越离谱了!以前各大模型拼参数、拼算力,现在画风彻底变了,一众顶级AI巨头,居然扎堆抢着收旧书、老文献,甚至不惜花大价钱把上百万本实体书拆掉扫描。 很多人看不懂,好好的高科技AI,怎么突然跟纸质书杠上了? 其实原因特别简单:网上能扒的公开数据,基本已经被AI薅干净了。现在大模型的竞争,早就不是技术参数的比拼,而是高质量独家数据的争夺战。 最近两件行业大事,直接戳穿了AI圈的最新内卷逻辑。 先说说Anthropic,操作真的简单粗暴。悄悄搞了个“巴拿马计划”,砸大钱从各大书店、图书馆收了数百万本实体书。然后用机器把书切开、压平,逐页高清扫描录数据,采集完直接把书本销毁。这还不是它第一次投机取巧,早年就靠盗版电子书训练模型,就连Meta也被曝光偷用盗版书籍数据,业内早就心知肚明。 巨头们何苦这么折腾?说白了就是传统识别技术太拉胯。稍微有点褶皱、光线不好、排版复杂的页面,机器就识别不出来。没办法,只能人工改造书本、适配机器,不仅费钱费力,效率还特别低。 不止Anthropic,GPT之父也盯上了老数据。他新出的Talkie模型,130亿参数,全程只学习1931年以前的旧报纸、古籍、专利和法律文献。最颠覆认知的是,这模型没见过现代代码,仅凭百年前的老旧知识,就能自学写出Python程序,足以证明实体古籍数据有多稀缺、多有用。 一边暴力拆书适配AI,一边手动录书啃老数据,两大巨头的操作,都印证了一件事:OCR才是当下AI竞争的隐形关键。百度文心刚更新的PaddleOCR-VL-1.6,直接拿下全球OCR综合性能第一,准确率冲破96.33%,把GPT、Gemini这些热门模型全都甩在了后面。 它最大的优势就是“不矫情”,不用拆书、不用压平页面、不用专门扫描,不管是歪的、皱的、手机随手拍的文档,都能精准识别。现在的OCR早就不是简单的识字工具了,而是AI打通现实世界的核心数据入口。在数据为王的时代,让AI主动看懂真实世界,才是真正的长远出路。