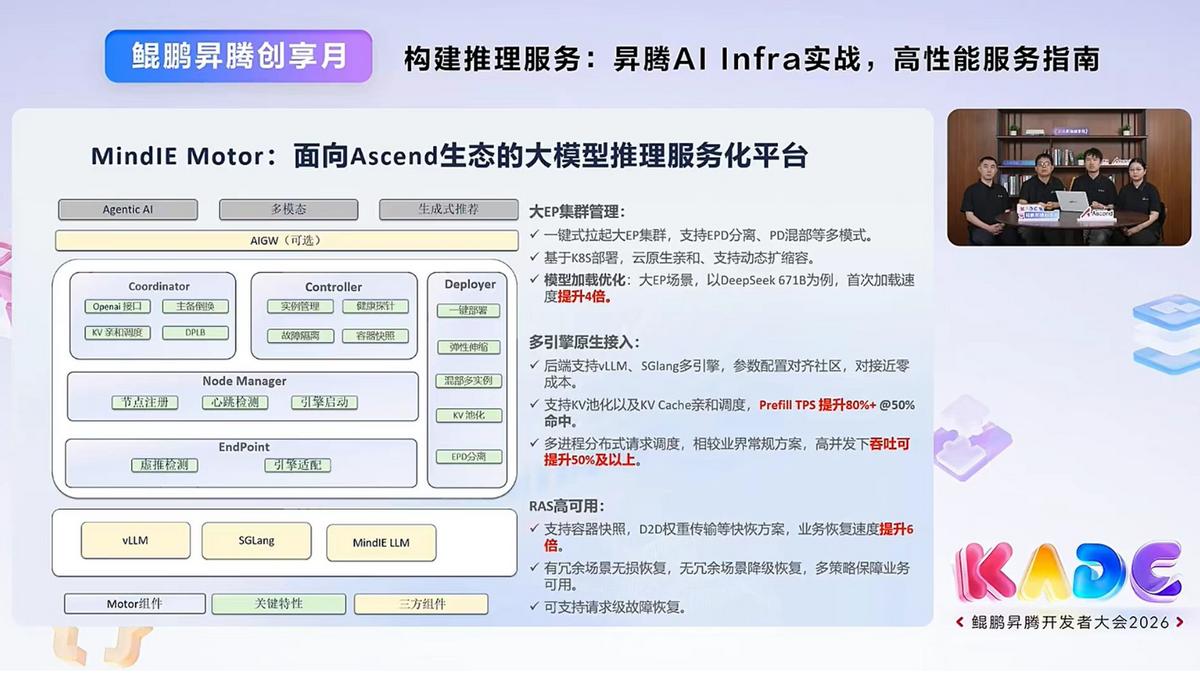
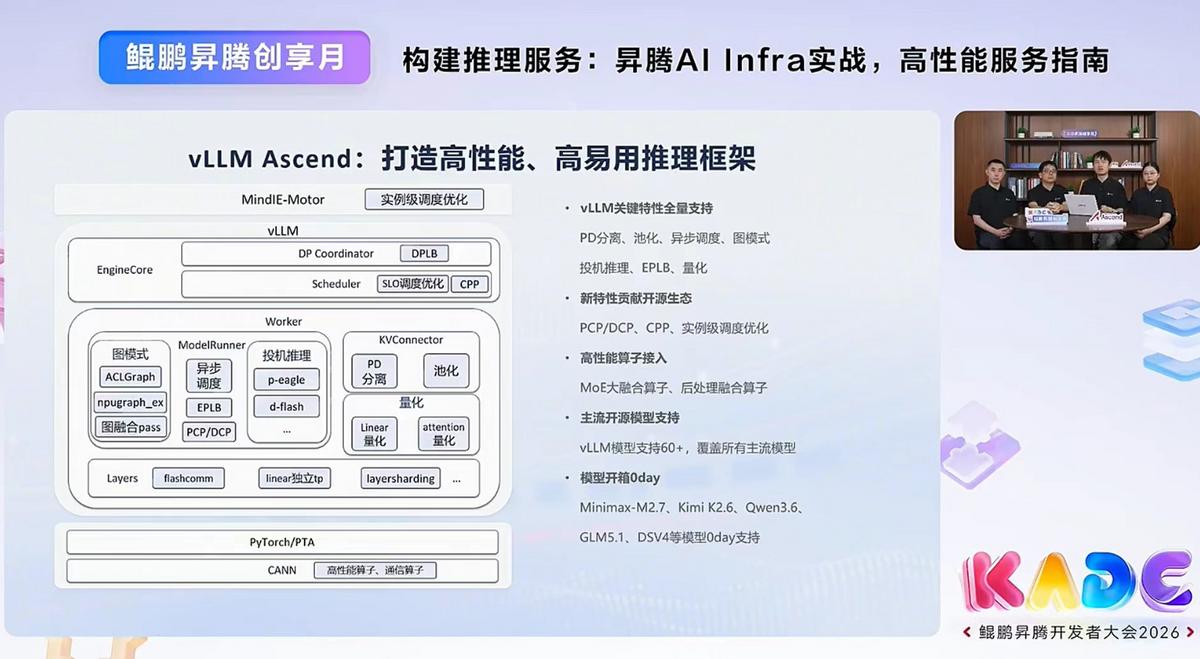
AI超级智慧背后的秘密竟是它!国内前沿AI推理系列方案发布,让AI更强大。 你发现没?今天,AI深度分析能力越来越强,正在加速渗入各行各业的核心环节。AI辅助CT诊断秒级标记出可疑病灶,辅助医生诊断;AI编程助手能根据指令,编写完整的Rust语言编译器,帮助更高效开发;AI自动驾驶能实时感知路况,在毫秒间判断前方障碍物并规划避让路径;AI金融风控通过扫描大数据,建立多维度客户动态信用画像,帮助评估信贷风险....... 这些无处不在的AI应用,展示了AI越来越强的推理能力。同时,也说明,AI要进一步发展,推理强化至关重要。 但推理要做得又快又省,并不容易。日前,在"鲲鹏昇腾创享月"直播中,华为昇腾技术专家团带来了AI推理的一套"全家桶"——全套昇腾AI推理软件,从调度、利用率、部署三个维度全面赋能推理性能。 首先,在调度方面,昇腾主要做的是让缓存“找对人”。你跟AI多轮对话时,很多内容之前其实已经算过一遍了,比如系统提示词、历史消息,这些重复的内容不需要每次重新算。但传统调度是"谁闲着派给谁",不管之前的数据存在哪,结果同一个问题在不同实例上反复计算。 昇腾MindIE Motor的KV亲和调度换了思路:先统一存好历史缓存,再建索引记录每份缓存在哪,调度时综合判断"哪个实例命中缓存最多"和"当前负载高不高",选出最合适的来处理。就像打车时平台不是派最近的车,而是派最顺路的车,省去绕路。实测Prefill吞吐提升80%以上(50%命中时),高并发整体吞吐提升超50%。 其次,是利用率方面,昇腾主要做的是让芯片“别空等”。推理过程中,调度逻辑和计算逻辑是串行的,调度做完才能算,算完才能调度下一轮,两轮之间芯片空等高达8-10毫秒。vLLM Ascend通过异步调度让两者并行,上一轮还在算,下一轮的调度就已经准备好了,在DeepSeek V3.1上,空泡从8-10毫秒降到100多微秒,低时延场景性能几乎翻倍。同时,HMA混合内存分配让不同类型请求在同一个池子里按需申请,KV Cache利用率提升至90%以上。 最后,是部署方面,昇腾主要做的是让大模型“跑得起”。大模型动辄几百GB,一台机器装不下就得跨机部署,跨机通信开销大、成本高。MindStudio工具链从量化切入:以Qwen3.5-397B-A17B为例,msModelSlim量化工具将模型从752GB压缩到220GB,精度损失不到1%,原来双机跨机才能跑的模型现在单机就能部署,硬件成本直降。 调度更聪明、算力更充分、部署更省心——昇腾AI推理软件栈,正在让AI推理更快、更稳、更简单。 鲲鹏昇腾创享月鲲鹏昇腾开发者大会2026昇腾超节点