技术巡猎 蔚来 泊车模型训练方法、泊车控制方法、智能设备及存储介质。自动泊车不是“能不能泊”这么简单的事情,对于用户来说,真正敏感的是过程。一台车从车位里出来时,如果一开始大幅摆动,轨迹曲率很大,离两边障碍物忽远忽近,哪怕最后成功泊出,用户也会很紧张。尤其是车位很窄、旁边停着车、前后空间有限的时候,系统每一次转向和换挡都会被放大。
这份蔚来智驾专利处理的就是泊出体验。端到端泊车功能的体验正在接近人类驾驶体验。泊出过程里,摇摆小、效率高、安心感高,是决定体验的关键。泊出和泊入还不一样,泊出初始空间更为受限,自车和周围障碍物距离近;初始阶段运动方向会强烈影响后续轨迹;不同车位类型,比如垂直车位、斜列车位和平行车位,泊出策略也不一样。
如果用一套统一策略去处理,就容易出问题,初始阶段轨迹稳定性不足,产生不必要的大幅转向或轨迹抖动;车位内轨迹曲率偏大,影响舒适性和可控性;车辆与两侧障碍物距离分布失衡,带来安全风险。
专利的方案,是基于泊出场景数据,用强化学习方法训练泊车模型。
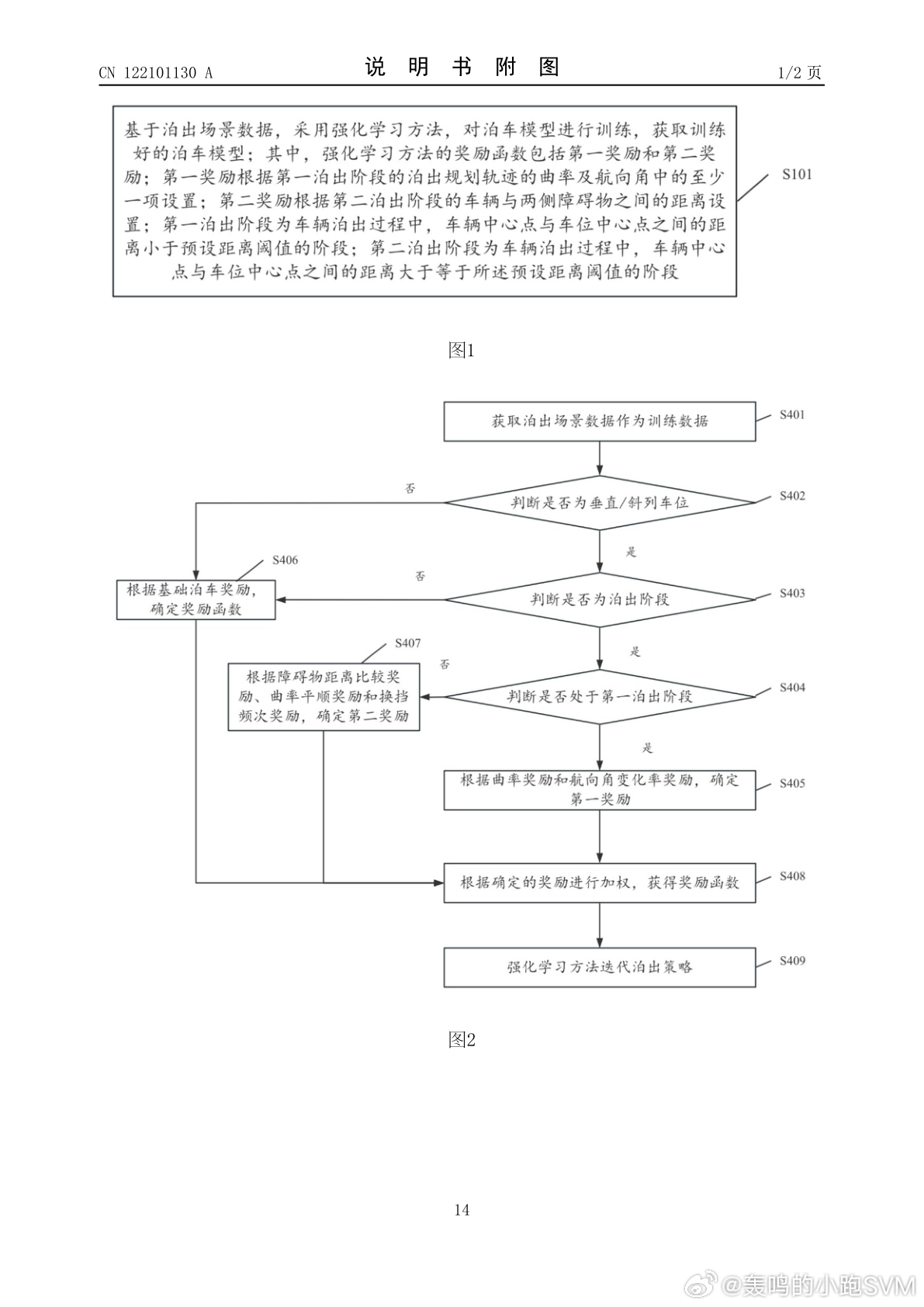
这里的关键是奖励函数。它把泊出过程拆成两个阶段。第一泊出阶段,是车辆中心点与车位中心点之间距离小于预设距离阈值的阶段;第二泊出阶段,是距离大于等于该阈值的阶段。
第一阶段的奖励,和泊出规划轨迹的曲率、航向角有关。比如瞬时曲率超过阈值,就给负向调整;航向角变化率过大,或者变化率本身波动太大,也会给惩罚,也就是说不鼓励车在刚出库时猛打方向、突然摆头。
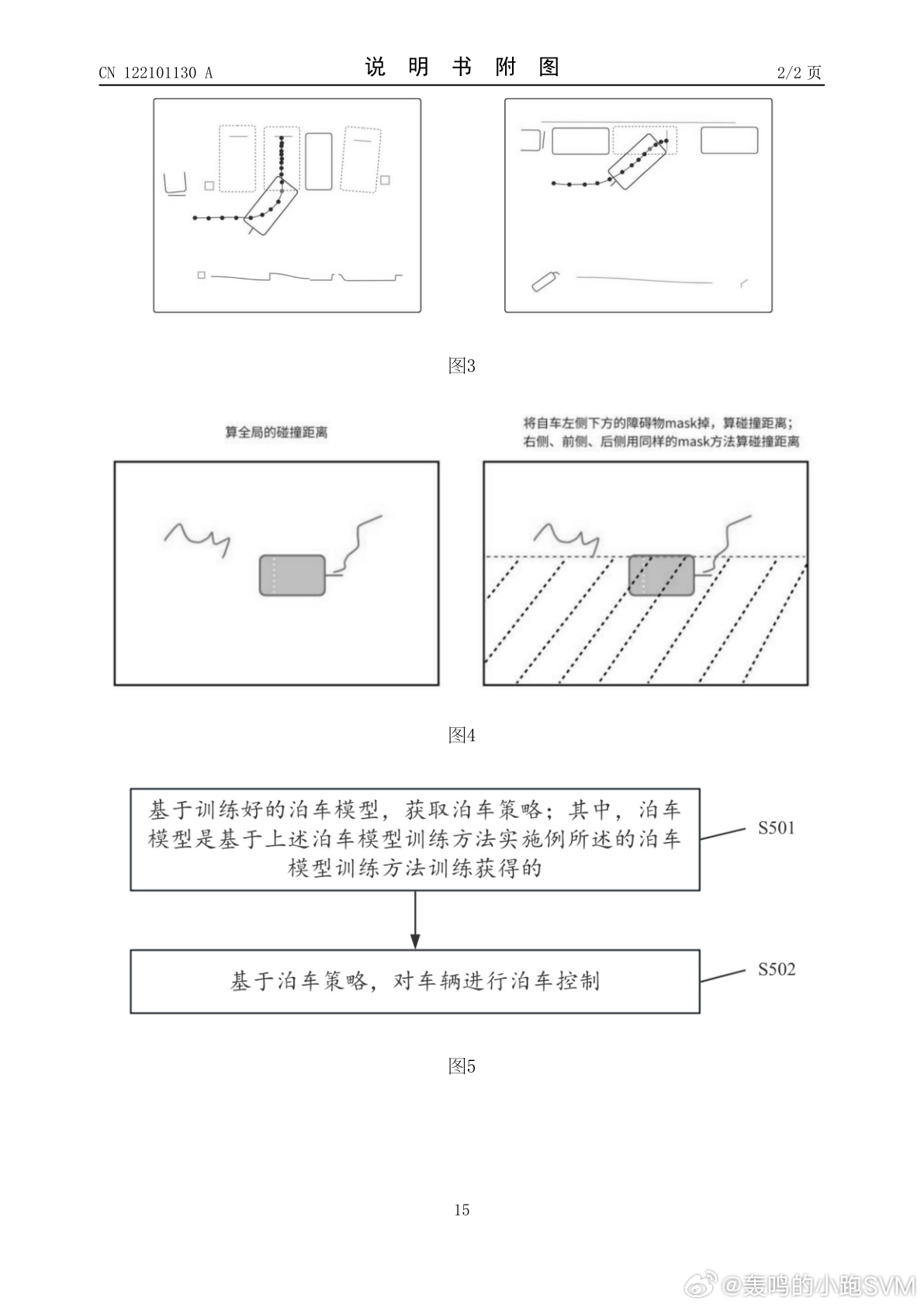
第二阶段的奖励,则关注车辆与两侧障碍物之间的距离。对于垂直车位或斜列车位,系统会实时获取车辆与车位两侧障碍物的最小距离,计算两侧距离比例。如果比例关系在预设区间内,给正向奖励;偏离区间,就给负向惩罚。后面还可以加入曲率平顺奖励、换挡频次奖励,以及速度、加速度、换挡次数、成功泊出、碰撞惩罚等基础泊车奖励。
这套方法的意思是,模型学到的不是“想办法出去”,而是“用更平顺、更均衡、更让人放心的方式出去”。
这很关键。因为泊车控制里的“成功”的定义非常粗暴。如果只看最后有没有离开车位,模型可能学会一些用户完全不喜欢的动作,比如大幅转向、频繁修正、靠近一侧障碍物再猛拉回来。人类驾驶员为什么让乘客更放心,不只是因为能出去,而是因为动作有预判,车身姿态和周围距离看起来都比较可控。
奖励函数就是在告诉模型什么叫“好”。曲率过大要扣分,航向角变化过猛要扣分,两侧距离失衡要扣分,换挡次数太多也要扣分。这样训练出来的泊车控制,才有机会从功能可用走向体验可信。
很多智能驾驶功能的问题,就在于动作不像人。自动泊车如果每次都贴着一侧障碍物走,或者反复大角度修正,用户会本能想接管。强化学习奖励函数如果只盯成功率,很可能学出激进动作;把曲率、航向角、两侧距离和换挡频次放进奖励里,这才能够把用户安心感写进训练目标。