给大家盘一盘理想自研的马赫 M100。
此前大家比较熟悉的是马赫 M100 的有效算力,单颗 1280 TOPS,因其采用数据流架构给算法软件更大的优化空间,单颗马赫 M100 的有效算力达到英伟达 Thor U 的 3 倍。
最近,一篇名为《M100: An Orchestrated Dataflow Architecture Powering General AI Computing》发表,理想汽车 CTO 谢炎为第一作者,这篇论文中,详细拆解了马赫 M100 的芯片架构(图二)。
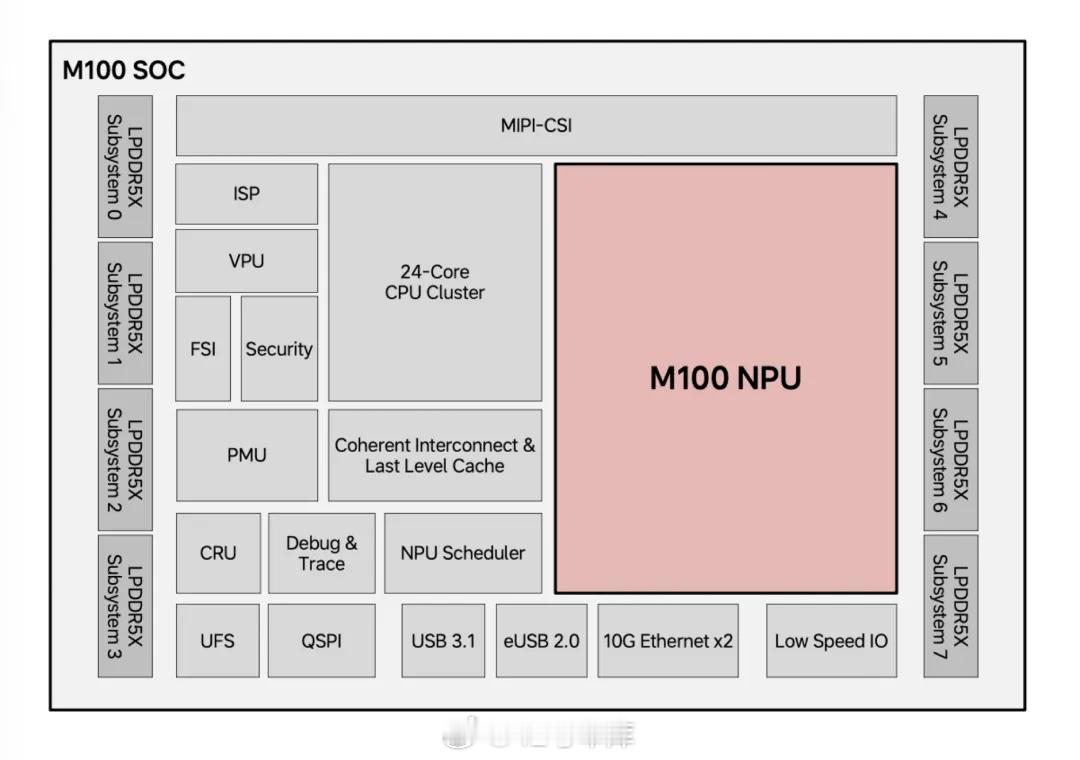
马赫 M100 芯片中,M100 NPU 占有最大的面积,NPU 的内部架构、内部通信方式以及 NPU 与其他核心的通信方式就非常重要(图三)。
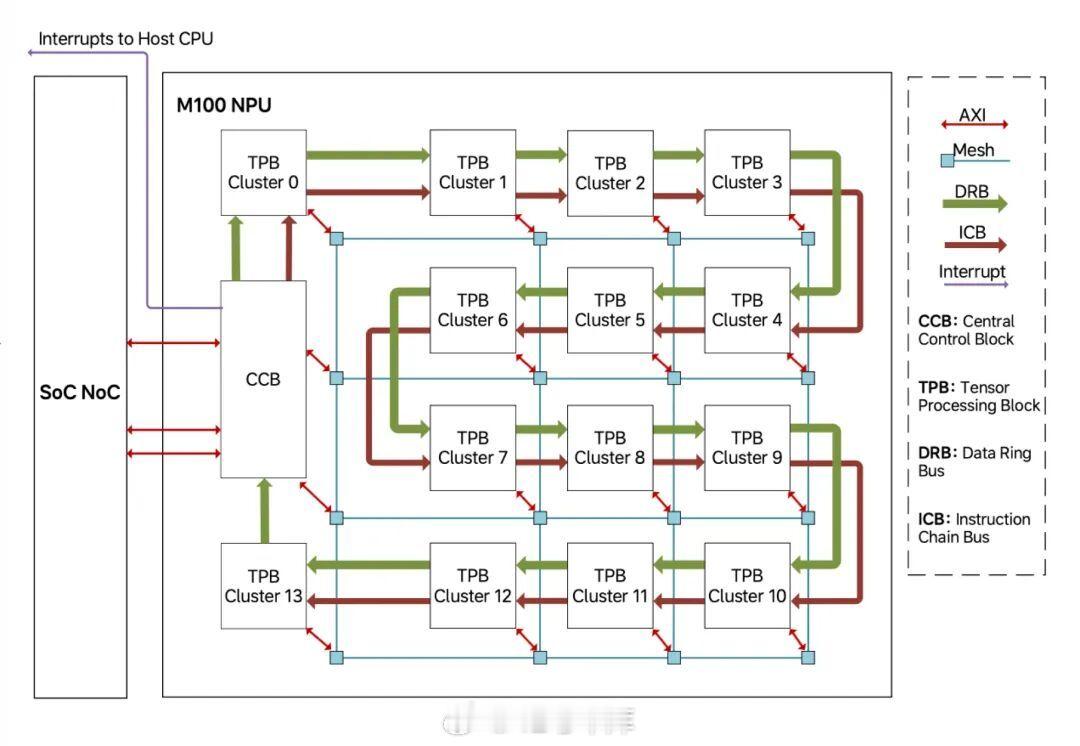
M100 NPU 与马赫 M100 其他核心通信主要通过三种方式:
- 2 个高带宽 AXI 主接口(每个 128 GB/s),让 NPU 直接访问 DDR 和 SoC 资源,而不像传统芯片还要让 CPU 喂数据。
- CPU 通过低带宽 AXI 与 NPU 通信,主要是下发任务、查询状态以及管理资源。
- 在 NPU 内部,拥有一个中央控制器(Central Control Block,CCB),以及 14 个张量计算(Tensor Processing Block,TPB)集群。每个集群中包含 4 个 TPB,因此整个 NPU 中共有 56 个 TPB。
为了满足 AI 推理中的数据传输需求,CCB 与 TPB 之间通过两套结构连接,分别是二维 Mesh 总线(2D Mesh Bus)以及数据环总线(Data Ring Bus,DRB)。
其中,二维 Mesh 总线为 TPB 集群、CCB、CPU、DMA 以及 SRAM 之间提供了可扩展、高带宽的点对点通信能力。在低拥堵的状态下,任意节点之间带宽最高 256 GB/s,还具备良好的扩展性。同时,DRB 提供了一条确定且高效的广播路径,总聚合带宽最高也是 256 GB/s,非常适合在多个 TPB 之间进行数据广播。具体是用 Mesh 还是 DRB,由软件决定。
另外还有指令链总线(Instruction Chain Bus,ICB)以菊花链的方式,将 CCB 与 TPB 集群连接起来,CCB 内部的 RISC-V 核心会通过 ICB 向单个或多个 TPB 下发指令。
除了最主要的 NPU 核心之外,马赫 M100 芯片还有以下主要模块(图二):
- 8 路 LPDDR5X 内存通道,共 64GB 容量,可实现最高 273 GB/s 带宽。
- CPU:24 核心 ARM Cortex-A78AE。
- 影像与感知:MIPI-CSI 是一个摄像头串行接口,支持 11 路视频输入;ISP 负责原始图像处理。
- 功能安全:功能安全岛(FSI:Functional Safety Island)和安全引擎(Security Engine)确保系统符合功能安全标准。
- 丰富的接口:集成了 UFS、USB 3.1 接口,以及 2 个 10Gb 以太网接口,还有多种低速接口。
新能源汽车42how李想称自研芯片被质疑跟风烧钱