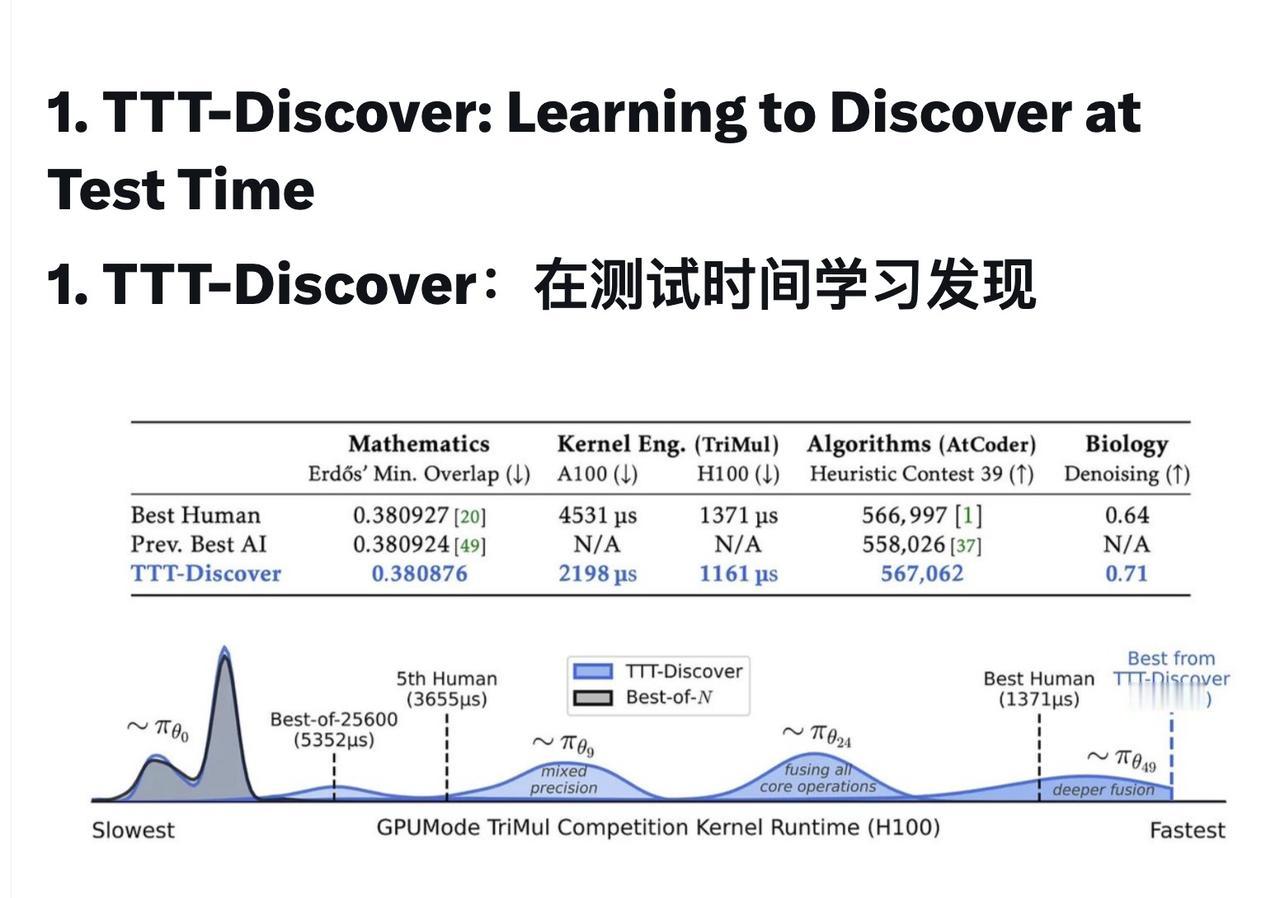
为科学发现引入了测试时训练机制,在测试时执行强化学习,使 LLM 能够持续地利用针对特定测试问题的经验进行训练。与 AlphaEvolve 等先前的工作(后者会冻结 LLM)不同,这种方法允许模型在尝试解决难题的过程中不断改进自身。 测试时强化学习: 该方法在由单个测试问题定义的环境中执行强化学习,其学习目标和搜索子程序旨在优先考虑最有希望的解决方案,而不是最大化跨尝试的平均奖励。 跨领域的最先进技术: TTT-Discover 在 Erdős 最小重叠问题、自相关不等式、GPUMode 内核竞赛(比现有技术快 2 倍)、AtCoder 算法竞赛以及生物学中的单细胞去噪方面创造了新的记录。