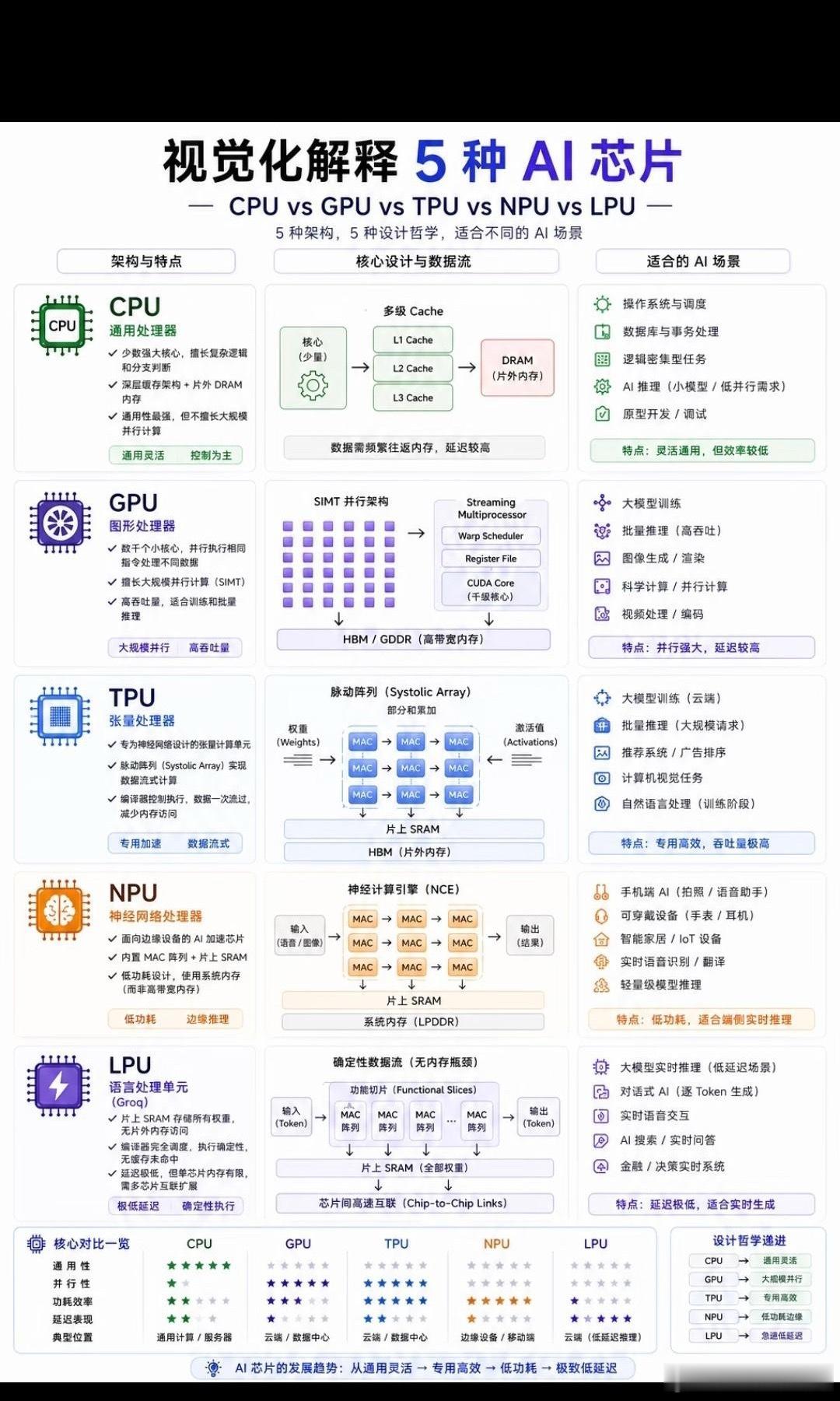
2026年了,AI芯片到底怎么选?一张图看懂CPU、GPU、TPU、NPU和LPU
现在的AI硬件圈可以说是“诸神黄昏”,从老大哥CPU到新贵LPU,名词满天飞。
其实,这五种芯片并不是谁取代谁的关系,而是为了适应AI从“训练”到“推理”,从“云端”到“边缘”不同阶段的产物。
我把这张图的核心逻辑提炼了一下,用大白话帮大家盘一盘这五位“狠角色”。
CPU:全能管家,但干不了粗活- 定位:计算机的大脑。- 特点:核心少而精,逻辑控制能力极强,但并行计算能力弱。- 痛点:让它跑大模型,就像让一位数学家去搬砖,虽然能搬,但效率太低,还费电。- 场景:系统调度、数据库、通用计算。
GPU:并行狂魔,算力界的“硬通货”- 定位:AI训练霸主(如NVIDIA H100)。- 特点:拥有数千个小核心,采用SIMT架构,擅长“大力出奇迹”的暴力计算。- 痛点:功耗高,且受限于“内存墙”,数据传输延迟较高。- 场景:大模型训练、图像生成、科学计算。
TPU:谷歌定制的“特种兵”- 定位:专用集成电路(ASIC)代表。- 特点:采用脉动阵列架构,数据像流水一样在计算单元中流动,极大减少了内存访问。- 痛点:通用性差,主要服务于特定生态。- 场景:云端大规模训练、推荐系统。
NPU:边缘设备的“省电小能手”- 定位:端侧AI加速器(如手机SoC中的NPU)。- 特点:专为低功耗设计,内置MAC阵列,擅长处理卷积等特定算法。- 痛点:性能上限不如GPU,不适合大规模训练。- 场景:手机拍照优化、语音唤醒、智能家居。
LPU:推理界的“闪电侠”- 定位:专为大语言模型推理而生(如Groq)。- 特点:采用确定性数据流架构,彻底移除缓存,权重全在片上SRAM,实现了极致的低延迟。- 痛点:片上内存有限,难以承载超大参数模型。- 场景:实时对话AI、高频交易、秒回问答。
一句话建议:训练大模型选GPU,手机跑AI靠NPU,想要对话秒回选LPU,而CPU永远是那个在幕后默默调度一切的基石。