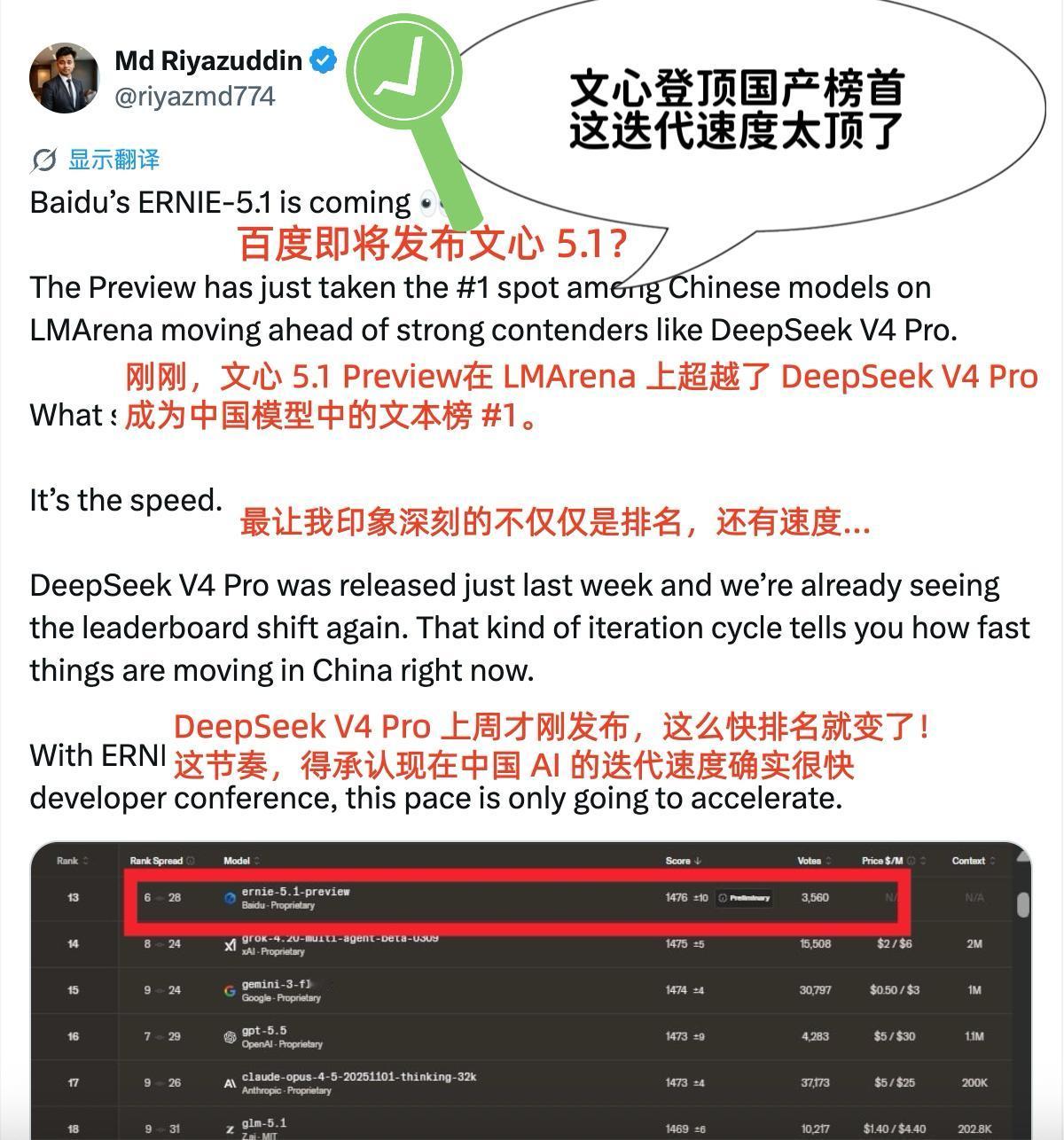
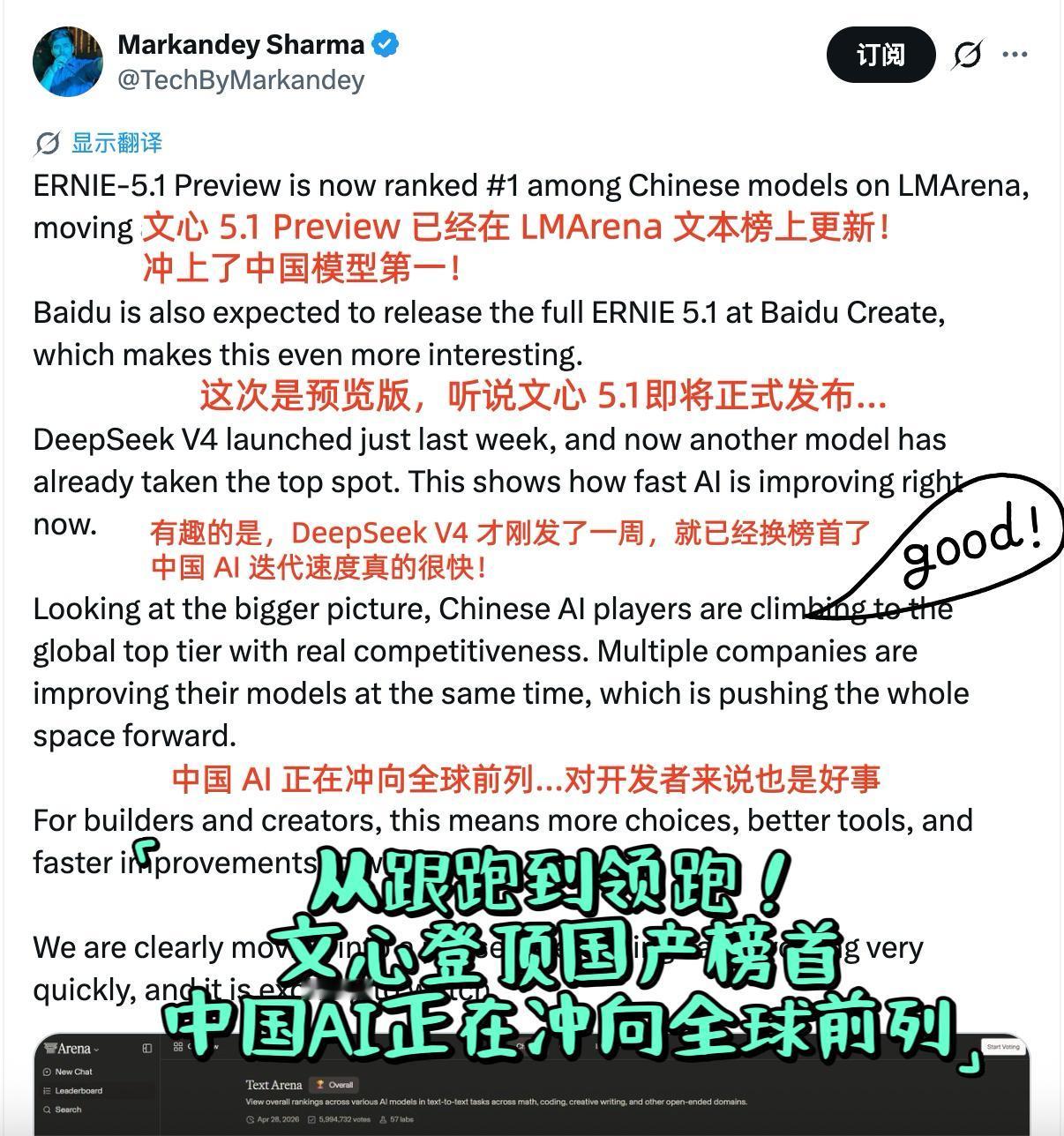
全球前十五的“唯一中国面孔”,文心5.1把国产模型推入第一梯队 LMArena榜单更新了,我特意翻了一下文本榜的前十五名。 一个很直观的感受是:这张榜单的前排,依然是海外模型的天下。GPT系列、Gemini、Claude、加上近期刚发布的DeepSeek-V4,强手如林。但仔细扫完前十五,会发现一个值得注意的细节——在这个全球最卷的AI文本能力竞技场里,文心5.1 Preview是前十五名中唯一一个国产模型。 “唯一”这两个字,放在今天这个节点,分量是很不一样的。 这两年国内大模型发展很快,隔三差五就有新产品发布,各种测评和榜单上也经常能看到国产模型的身影。但“能见到”和“能在最核心的赛道上独自扛旗”是两回事。LMArena文本榜的排名机制是靠匿名对战、用户投票打出来的,做不了假,拼的就是纯粹的文本理解和生成能力。在这样一个充分竞争的场子里,前十五名里只剩一个中国面孔,说明在绝对实力层面,国产模型的顶尖选手其实并不多。 文心这次能成为那个“唯一”,背后是有原因的。 我关注到的一些信息显示,这版5.1 Preview能做到这个水平,和文心5.0时期打下的底子关系很大。当时提出的“多维弹性预训练”,核心思路是通过一次训练产生多种规模的模型,把训练效率拉到了一个很夸张的程度。这次的Preview版本就是基于这套技术训练的,据说预训练成本只有业界同规模模型的6%左右,但基础效果已经跑到了全球前排。花更少的资源做到更好的表现,这种技术路线的选择,可能才是文心能从一众国产模型中跑出来的真正原因。 还有一个时间点值得留意。百度Create 2026大会5月份就要开了,不出意外的话文心5.1正式版本会正式亮相。现在的Preview版本已经能冲到LMArena前十五、国产第一的位置,正式版迭代之后能到什么程度,说实话有点期待。 目前Preview版已经在百度千帆上开了邀测,开发者可以先上手体验。对于国内的AI开发者来说,全球第一梯队里有一个自己家的模型可供调用和测试,本身就是件挺踏实的事。 毕竟,不管行业怎么发展,核心技术榜单的第一梯队里,得有自己的位子。文心这次,算是把这个位子坐住了。 百度 文心 文心大模型