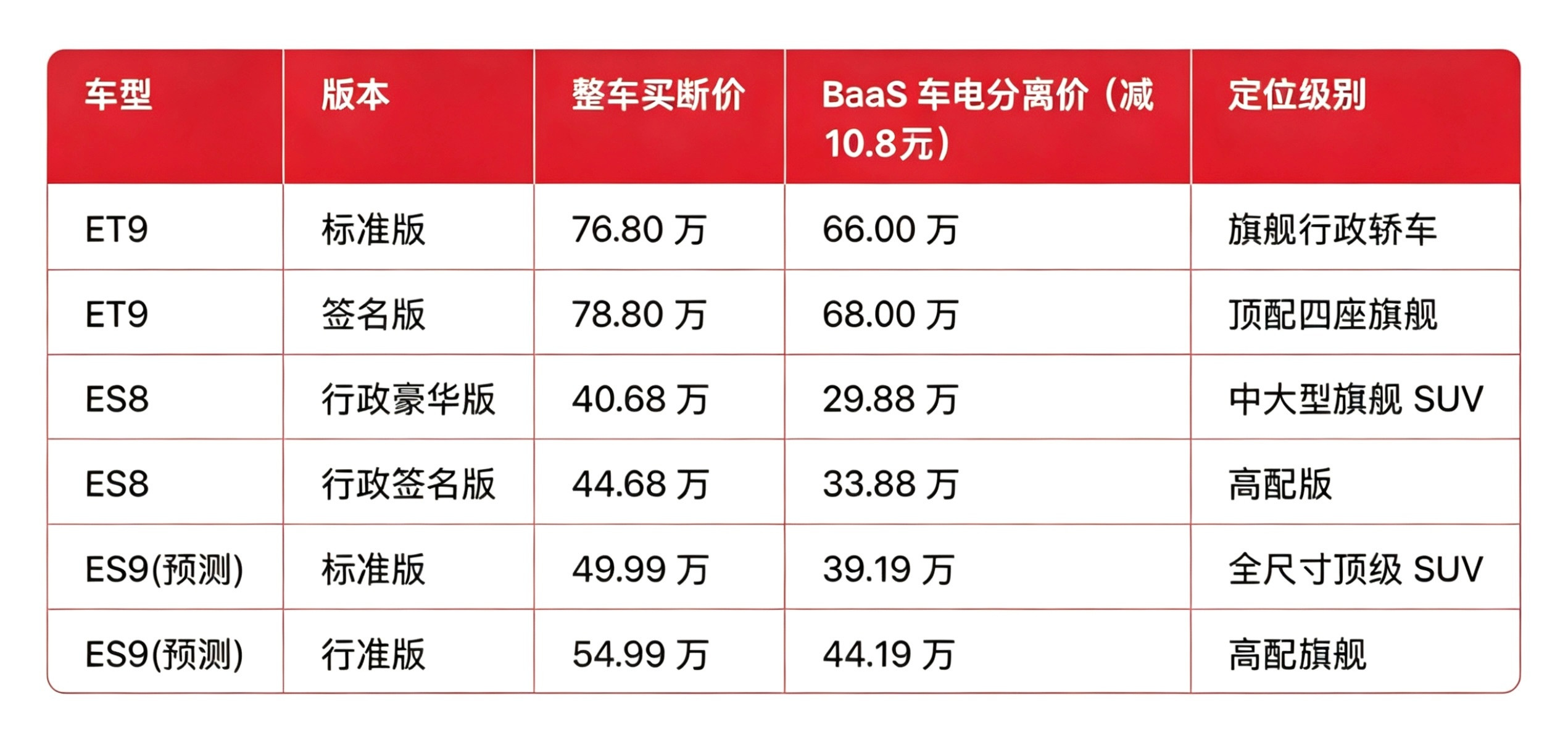
本以为横空出世的DeepSeek,是去跟硅谷巨头硬刚的国货之光。弄了半天,梁老板端着世界级的AI模型,转身扎进交易市场磨刀霍霍。这哪是同台竞技,这是赤裸裸的降维屠杀。 梁文锋的路子,跟其他AI创业者完全不一样。别人是先烧钱做模型、拉融资、再想着商业化,他倒好,从一开始就攥着两条腿走路。 2008年全球金融危机那会儿,还在浙江大学读研的梁文锋就带着团队,用机器学习技术探索全自动量化交易。这条路起步并不顺,8万本金几乎赔光,但他没放弃。硕士毕业后,他没进大厂,反而在成都九眼桥的廉价出租屋里演算自己的模型。 2015年,梁文锋正式成立杭州幻方科技有限公司。那一年A股市场波动,幻方依靠先进的高频量化策略取得了令人瞩目的成绩。到2015年底,梁文锋已凭借每年超过100%的复合收益率,跻身亿万富豪行列。 2016年10月21日,幻方推出第一个AI模型,实现了所有量化策略的AI化转型。到2017年底,公司几乎所有的量化策略都已经采用AI模型计算。2018年,幻方正式确立了以AI为核心的发展战略。随着业务快速扩展,算力瓶颈显现。2019年,梁文锋带领团队自主研发了“萤火一号”训练平台,总投资近2亿元,搭载了1100块GPU。同年,幻方资金管理规模突破百亿元。 2020年,“萤火一号”AI超级计算机正式投入运作,号称可以匹敌4万台个人电脑的算力。2021年,“萤火二号”的投入增加到10亿元,搭载了约1万张英伟达A100显卡。也就在这一年,幻方的资产管理规模突破千亿大关,跻身国内量化私募领域的“四大天王”之列。 量化交易给梁文锋带来了惊人的财富积累,幻方量化2025年的收益均值达56.55%,在中国管理规模超百亿的量化私募业绩榜中位列第二。公司近三年的收益均值为85.15%。 有了雄厚的财力支撑,梁文锋在2023年5月宣布进军通用人工智能领域。同年7月,幻方量化宣布成立大模型公司DeepSeek。DeepSeek的发展速度快得惊人。2024年5月,DeepSeek发布了DeepSeek-V2模型。其API定价为每百万tokens输入1元、输出2元,价格仅为GPT-4 Turbo的百分之一。同年12月27日,DeepSeek-V3面世,并公布了长达53页的训练和技术细节。 2025年1月20日,DeepSeek正式发布DeepSeek-R1模型。这款模型在“数学、代码和推理任务”方面的表现可与OpenAI的o1模型相媲美,同时仅使用一小部分计算能力。 市场反应极为强烈,DeepSeek-R1模型发布后,2025年1月DeepSeek用户增长达1.25亿。2025年1月27日,DeepSeek-V3在苹果中国地区和美国地区应用商店免费APP下载排行榜中排名第一,在美区下载榜上排名超过ChatGPT。 更深远的影响是,DeepSeek的崛起直接冲击了全球芯片巨头。2025年1月27日,美股芯片板块盘前领跌,英伟达因此市值一度蒸发6000亿美元。 与此同时,中国三大基础电信企业——中国移动、中国电信、中国联通均全面接入DeepSeek开源大模型。百度智能云千帆平台、阿里云计算有限公司的PAI Model Gallery、昇腾社区也都上线了DeepSeek-V3模型。 梁文锋的商业模式彻底颠覆了全球AI竞争的规则,其他AI公司还在为融资发愁时,他已经用金融市场的利润为自己打造了一个不差钱的研发堡垒。当竞争对手不得不考虑商业化变现时,他可以纯粹专注于技术突破。这种从量化交易到AI大模型的路径,不是简单的业务延伸,而是完整的生态闭环。 梁文锋用事实证明,在AI这场世纪竞赛中,有时候换条赛道,比在原有赛道上拼命追赶更有效。当所有人都在讨论中国AI落后美国多少年时,他用557.6万美元的成本,做出了媲美7800万美元投入的模型。这已经不是技术追赶,这是商业模式的降维屠杀。