【一句“嘿”吞掉22%用量配额,Claude的计费逻辑你可能从没搞清楚】
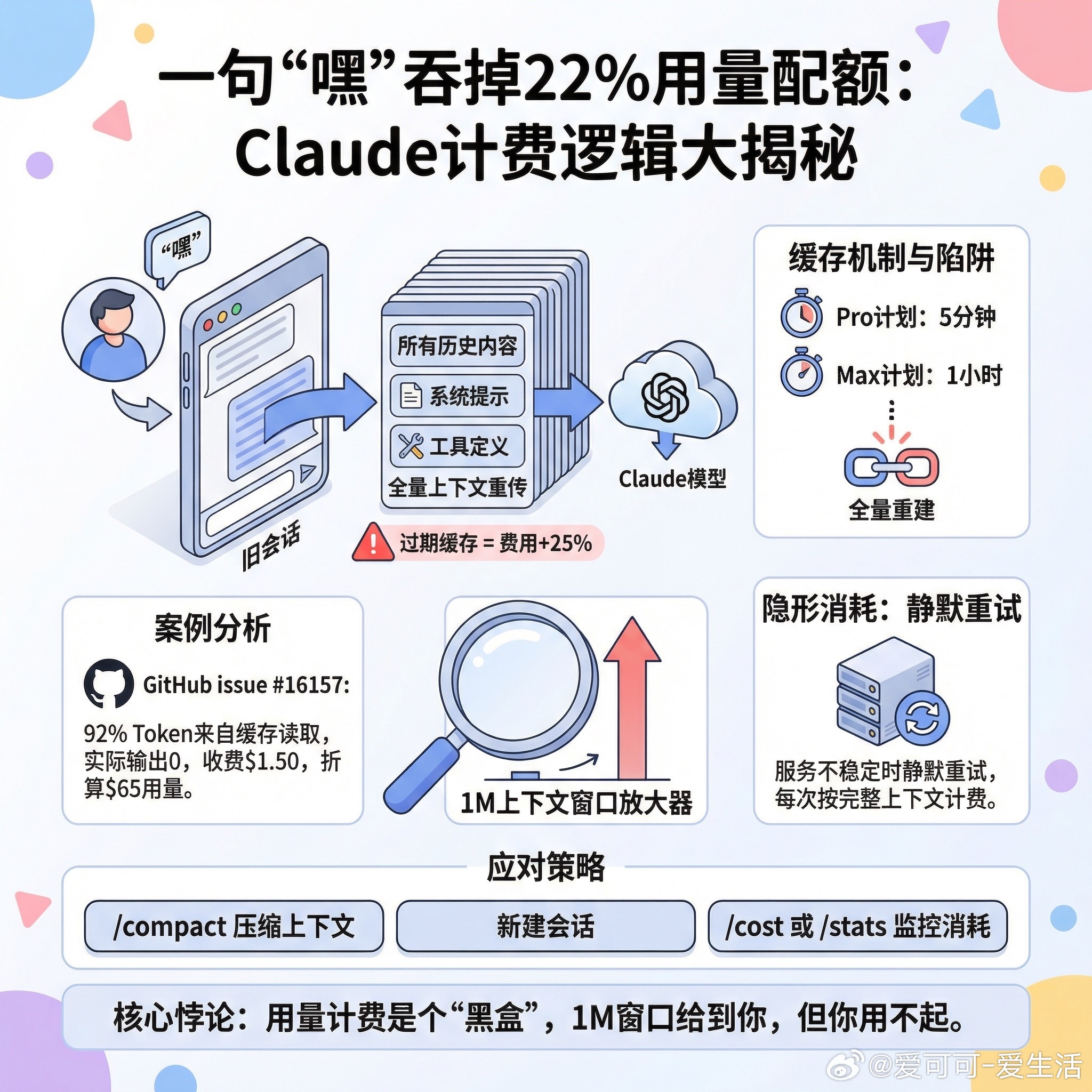
快速阅读: 有用户发现对一个久置的Claude Code会话发了句“hey”,用量暴涨22%。这不是bug,而是LLM的底层工作机制——每条新消息都会把整个对话历史重新发送一遍。叠加缓存过期、1M超长上下文等因素,账单会失控得很优雅。
---
每次你在一个旧会话里发消息,你不是在发那条消息。你是在把这个会话里所有的内容、系统提示、工具定义,全部重新塞给模型一遍,然后再加上你那句“hey”。
Claude Code有缓存机制,活跃会话期间的上下文读取成本会打一折。但这个缓存有过期时间:Pro计划5分钟,Max计划1小时。放了一夜再回来,缓存早就没了。你的那句“hey”触发的是一次全量重建,费用比正常输入还要贵25%。
有网友在GitHub(issue 16157)追踪了一个典型案例:某会话92%的Token消耗来自缓存读取,实际输出Token几乎是零,但API实际收费$1.50,被折算成了$65的用量。
1M的上下文窗口是个放大器。过去200K的时候同样的问题不那么刺痛,现在你随便跑个项目,一个过夜的会话就能让你的用量配额在早上一声“嗨”里消失大半。
有观点认为,当Claude遇到服务不稳定时,它会静默重试请求,而每次重试都按完整的上下文长度计费。你以为卡住了,实际上它在一遍一遍地读你的所有历史记录。
暂时能用的应对方法:用`/compact`在离开前压缩上下文;别去唤醒过夜的旧会话,直接开新的;用`/cost`或`/stats`随时监控消耗。
有网友提到,更根本的问题在于用量计费完全是个黑盒,同样的操作今天用20%,明天可能用89%,没有任何预警。Anthropic到目前为止没有正式回应。
1M上下文窗口给到你,但你用不起——这个悖论大概才是真正该讨论的问题。
ref: www.reddit.com/r/ClaudeAI/comments/1s3hh29/saying_hey_cost_me_22_of_my_usage_limits
AI创造营人工智能