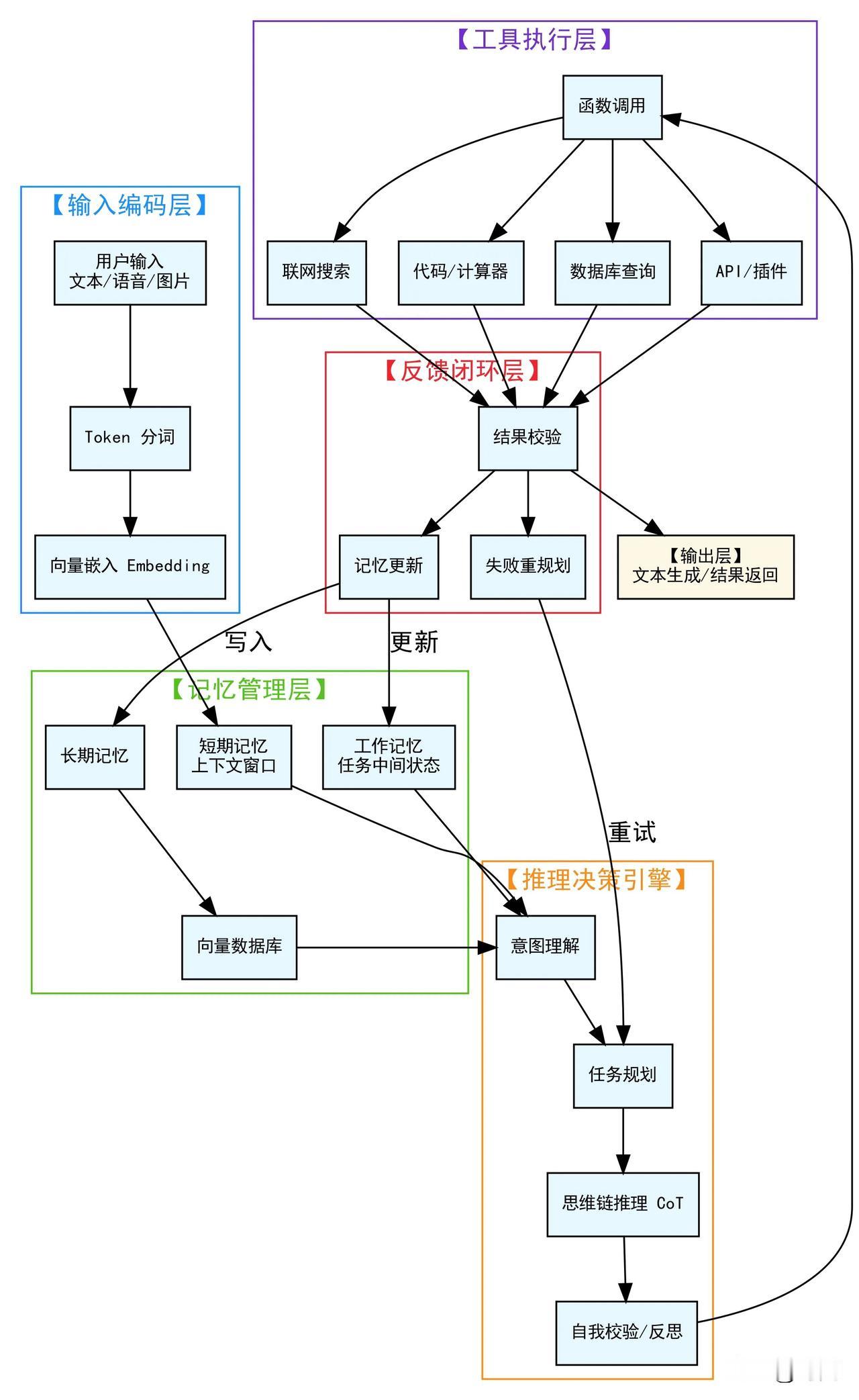
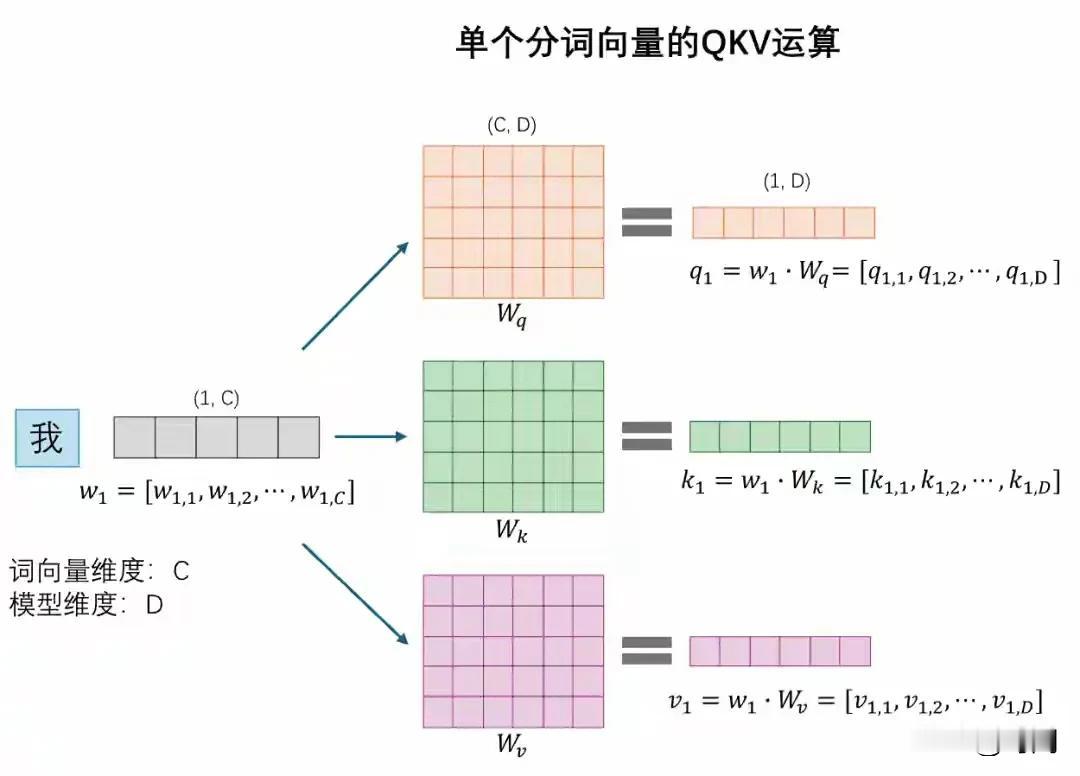
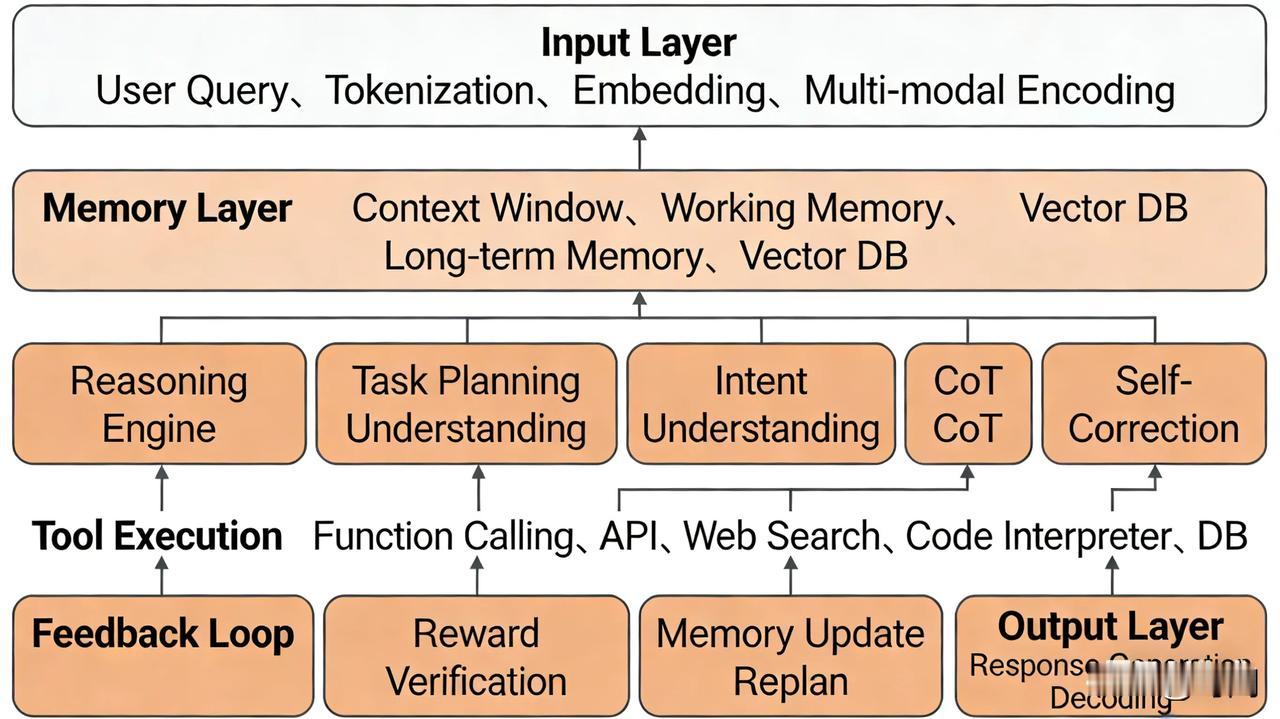
一篇文章理解AI大模型,外行人终于不再把豆包当神了!目前全球95%的AI应用软件都是基于谷歌之前公开的一篇论文,主要讲的就是一个编程思想Transformer-编码解码注意力机制。 随后国外根据这个理论基础研发了对话大模型chatGPT。他的核心原理就是将用户的输入文字拆分为系统可识别的字或词(token)。然后经过大量的预先设计好的重复点积数组矩阵函数运算,依次计算出下一个回答你的字词,最终形成一段文字输出给你。 懂一些计算机软件的看这里:大模型搭建部署完毕后,初始状态是有N个分词token的一维浮点数值,以及X层的QKV二维权重矩阵数组,此时内部全部是随机值。所谓的训练大模型其实就是利用全世界的书籍、文献、资料、数据等来运行计算,逐渐自动调整token的一维浮点数值和每层QKV二维权重矩阵值,达到“自动推测下一个字词的目的”。 因此,无论是chatGPT,还是豆包、千问、元宝等大模型系统,最值钱的核心的软件数据就是他们内部训练完毕的“所有分词token对应的浮点数组数据和各层QKV权重矩阵值”,价值占大模型软件资产的90%。据说当前的豆包64层、120k分词、4096纬度的版本训练一次就得2个亿。 如何理解大模型Transformer思想? 当今AI大模型的本质和原理 一段话解释智能AI对话原理








李961391415
有问题我找豆包,我管你什么大模型思想干什么?