scaleFabric发布会,我个人感觉是国产智算这几年最提气的一次。 为什么这么说? 万亿大模型时代有个非常现实的问题: 算力越大,网络越关键。
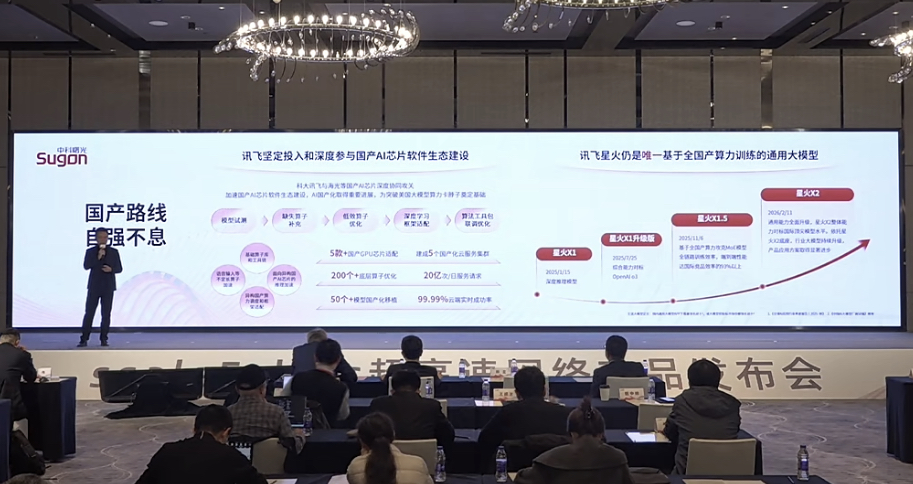
科大讯飞AI工程院架构师鲍中帅在现场讲得很直接: 数据并行、流水并行、张量并行,这些大模型训练方式,本质上全是节点之间疯狂通信。 网络慢一点,效率直接腰斩。 所以过去很多万卡集群为什么都绕不开IB? 因为没有更好的选择。
而 scaleFabric 的出现,等于是国产原生RDMA网络第一次真正走到台前。 很多行业人听完之后的感受只有一句: 以前我们算力要追赶芯片, 现在我们已经可以自己修算力高速路了。