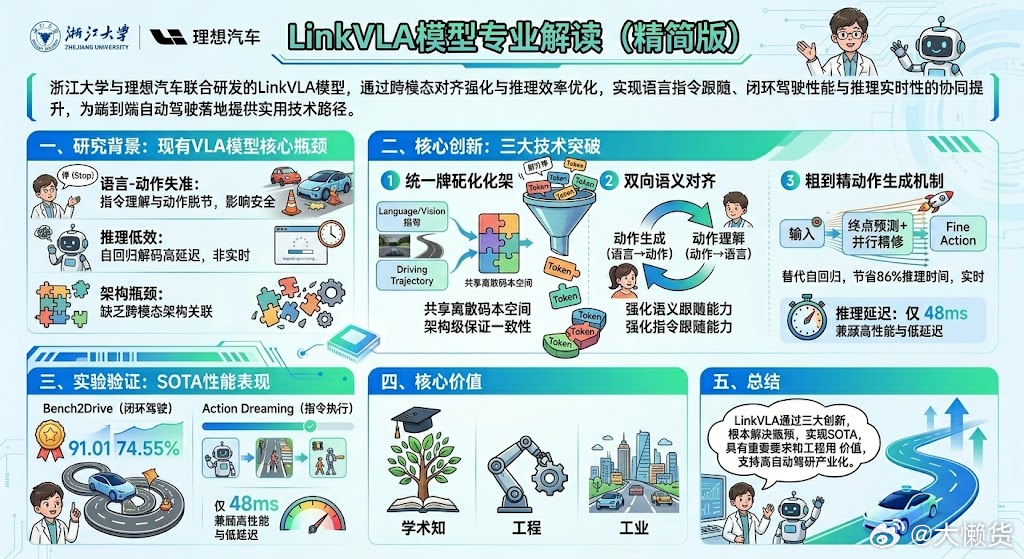
这篇由浙江大学和理想汽车联合研发的论文,提出了一款名为LinkVLA的全新自动驾驶模型,核心解决了当下自动驾驶中 “语言指令和实际操作脱节”“运算速度慢” 两大关键问题
论文链接:网页链接
一、解决的核心痛点过去的自动驾驶视觉 - 语言 - 动作(VLA)模型,存在两个明显问题:
“听不懂” 指令:比如人类说 “向左变道”,模型可能理解了但实际开出来的路线却是保持原车道,语言指令和实际驾驶动作脱节,影响安全性;
“反应慢”:模型生成驾驶动作时是一步一步计算,像人慢慢数步数,运算耗时久,实际驾驶中容易出现延迟,不适合真实道路场景。
二、LinkVLA 的三大 “创新妙招”,既懂指令又提速为了解决上述问题,研究团队给模型设计了三个核心改进
※简单来说就是※①统一 “语言” 和 “动作” 的表达②让模型学会 “双向理解”、把慢运算改成 “两步快运算”:③给语言和驾驶动作做 “统一翻译”
把人类的语言指令(如 “加速”“绕开施工区”)和汽车的驾驶动作(如走哪条路线、加减速),都转换成模型能统一识别的 “数字代码”-,就像给两者制定了同一种 “语言”,从根源上避免模型理解指令和执行动作时出现偏差。
同时针对驾驶动作的精准性做了优化,比如车辆附近的路线会计算得更细致,让变道、跟车这些近距离操作更准确。让模型学会 “双向思考”,更懂指令
不仅训练模型 “听懂指令做动作”(比如听到 “减速” 就踩刹车),还训练它 “看自己的驾驶动作,反过来说出对应的指令”(比如看到自己在减速,能说出 “因为前方有车,所以减速”)。
这种双向训练让模型对语言和动作的关联理解更深刻,就像人既会听指令做事,也会解释自己做的事,自然能更精准地跟着人类指令开。并且这个改进让模型的运算耗时直接减少了 86%,解决了 “反应慢” 的问题,同时还能保证路线的准确性。
三、实际测试效果:驾驶更稳、指令执行更准、速度还快
在专业的自动驾驶模拟测试平台(CARLA)上,LinkVLA 的表现远超之前的主流模型,综合驾驶评分达到 91.01,成功率 74.55%,;面对 “加速”“变道”“停车” 等不同语言指令,整体执行成功率达到 87.16%,尤其是变道、加速这些高频指令,执行准确率接近 97%;优化后的运算速度,仅比最快的传统模型慢一点点(每步 48ms vs 34ms)
简单来说,LinkVLA直接把语言和轨迹塑造成了同一种数字语言,从源头上不再需要翻译,让其具备了真正的语义稳定性。