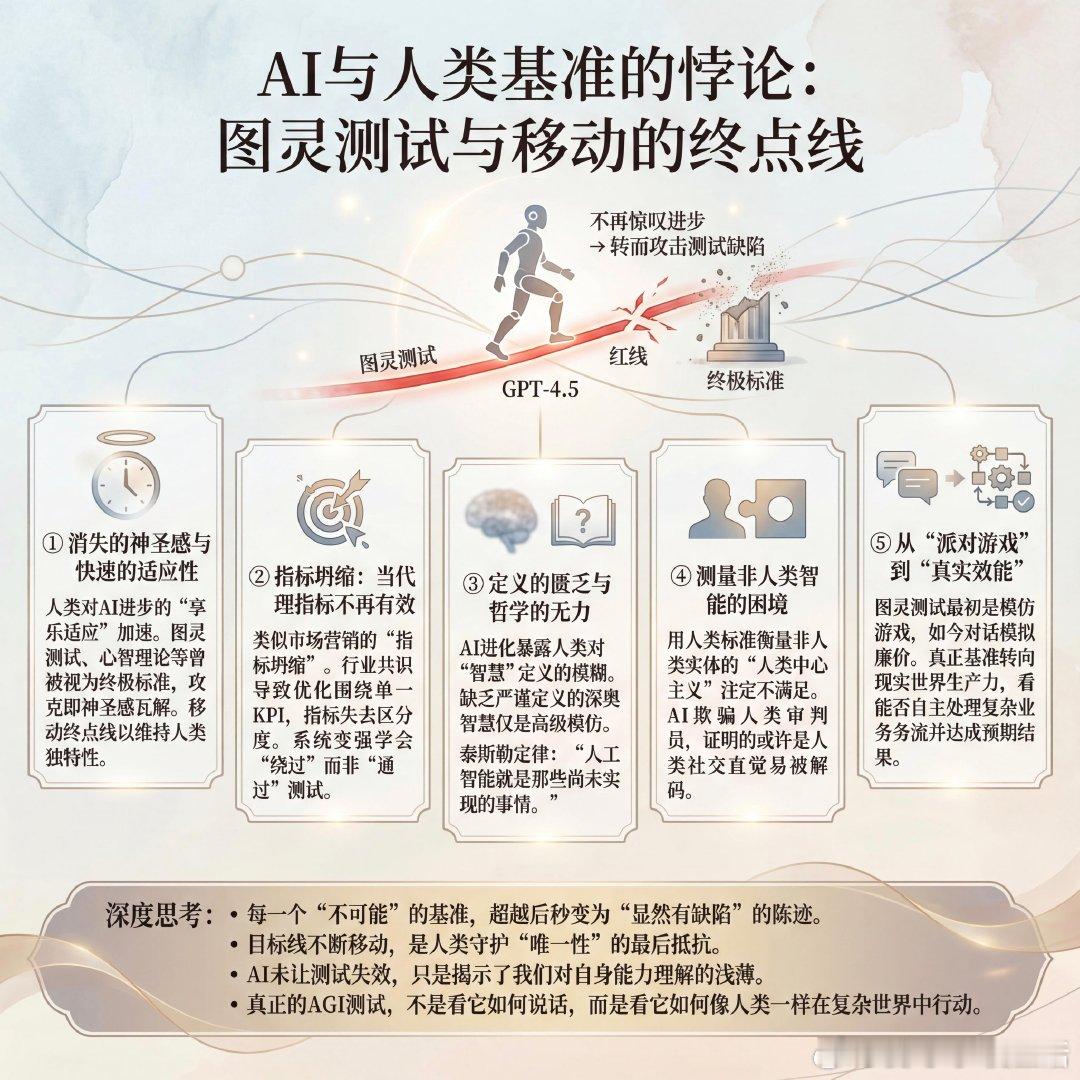
图灵测试曾被视为人工智能领域一座不可逾越的高山,但当 GPT-4.5 真正跨越这条红线时,人们的反应却出奇地一致:不再惊叹于机器的进步,而是转而攻击测试本身存在的缺陷。这种现象揭示了我们与人工智能相处时一个有趣的悖论:每当一个“不可能”的基准被突破,它就会从神坛跌落,瞬间变成一个“显然有误”的过时指标。以下是关于这一现象的深度思考:1. 消失的神圣感与快速的适应性人类对 AI 进步的“享乐适应”正在加速。图灵测试、心智理论(Theory of Mind)甚至未来的 ARC-AGI,这些曾被视为衡量智能、创造力或意识的终极标准,在被攻克的那一刻,其神圣感便随之瓦解。我们习惯于移动终点线,以维持人类智能的独特性。2. 指标坍缩:当代理指标不再有效在人工智能领域,存在一种类似市场营销的“指标坍缩”现象:一旦行业在某个关键绩效指标(KPI)上达成共识,所有的优化都会围绕这个指标进行,最终导致该指标失去区分度。测试并没有变差,只是系统变强了,强到学会了如何“绕过”测试而非“通过”测试。3. 定义的匮乏与哲学的无力AI 的进化正在暴露人类数千年来对“智慧”定义的模糊与匮乏。我们发现,许多所谓的深奥智慧,在缺乏严谨定义和衡量标准的情况下,其实只是某种高级的模仿。正如泰斯勒定律(Tesler's Theorem)所言:“人工智能就是那些尚未实现的事情。”4. 测量非人类智能的困境我们目前所有的测试方法,本质上都是在用衡量人类的标准去套用非人类实体。这种“人类中心主义”的测量方式注定是不满足的。当 AI 能够通过模仿欺骗人类审判员时,它证明的或许不是它拥有了人类的心智,而是人类的社交直觉其实比我们想象中更容易被解码。5. 从“派对游戏”到“真实效能”图灵测试最初的构想更像是一种模仿游戏。如今,单纯的对话模拟已成为一种“廉价”的技巧。真正的基准正在从实验室的测试集转向现实世界的生产力。一个智能系统是否真正具备价值,不再看它能否在聊天中伪装成人类,而在于它能否自主处理复杂的业务流,并达成人类预期的结果。思考:- 每一个“不可能”的基准,在被超越后的秒速内,都会变成“显然有缺陷”的陈迹。- 目标线的不断移动,本质上是人类在面对机器崛起时,为了守护“唯一性”而进行的最后抵抗。- AI 并不是让测试失效了,它只是揭示了我们对自身能力的理解有多么浅薄。- 真正的 AGI 测试,不是看它如何说话,而是看它如何像人类一样在复杂世界中行动。x.com/emollick/status/2004355265802670409