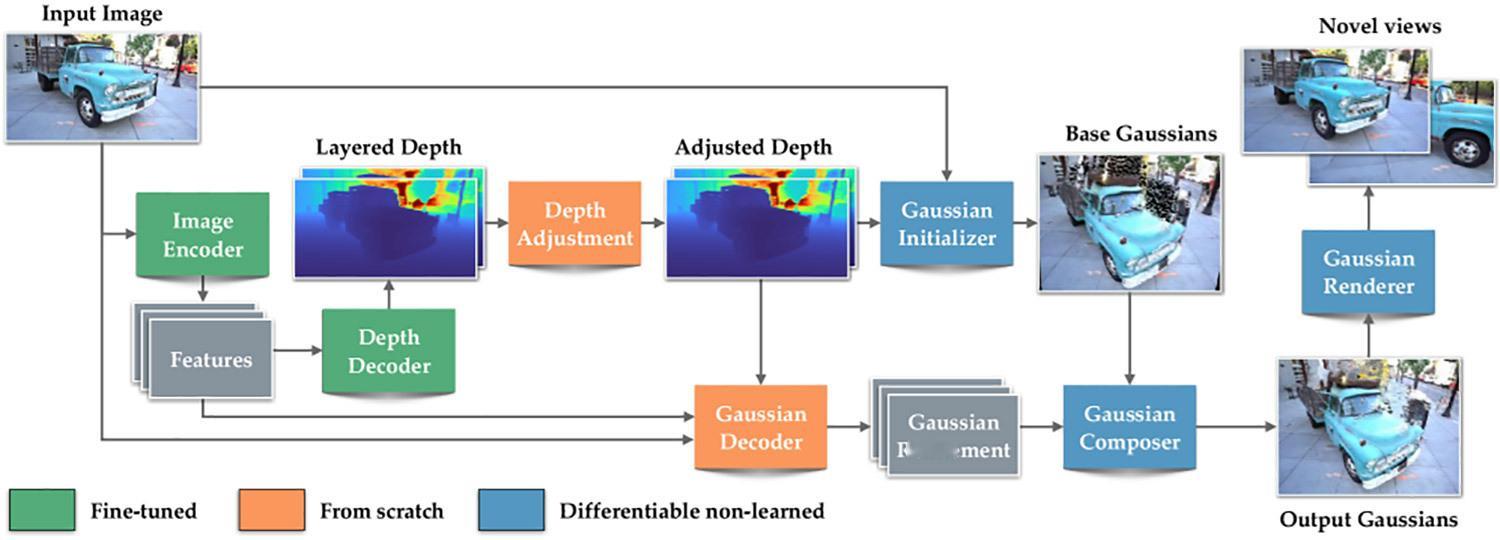
【Apple 发布了一款开源模型,可即时将 2D 照片转换为 3D 视图】Apple 发布了一项名为“Sharp Monocular View Synthesis in Less Than a Second”的研究报告,详细说明了它如何训练一个模型,从单个 2D 图像重建 3D 场景,同时保持距离和比例在现实世界中保持一致。我们提出了一种名为 SHARP 的方法,它基于单张图像合成逼真的视图。给定一张照片,SHARP 通过回归模型来估计所描绘场景的三维高斯表示的参数。在标准 GPU 上,只需通过神经网络进行一次前馈传递,即可在不到一秒的时间内完成此操作。SHARP 生成的三维高斯表示可以实时渲染,从而为附近的视图生成高分辨率的逼真图像。该表示采用度量尺度,具有绝对尺度,支持度量尺度的相机运动。实验结果表明,SHARP 能够在不同的数据集上实现稳健的零样本泛化。它在多个数据集上取得了新的突破,与最佳先验模型相比,LPIPS 降低了 25-34%,DISTS 降低了 21-43%,同时合成时间缩短了三个数量级。三维高斯函数本质上是一个位于空间中的小型、模糊的色光团。当数百万个这样的色光团组合在一起时,它们可以重建一个从特定视角观看精确的三维场景。为了创建三维高斯表示,大多数三维高斯分布方法需要从不同视角拍摄同一场景的数十张甚至数百张图像。相比之下,SHARP 模型只需一张照片,即可通过神经网络的一次前向传播预测完整的三维高斯场景表示。为了实现这一目标,Apple 利用大量的合成数据和真实世界数据对 SHARP 进行了训练,使其能够学习多个场景中常见的深度和几何模式。因此,当给定一张新照片时,该模型会估计深度,利用它所学到的知识对其进行提升,然后在一次处理中预测数百万个三维高斯的位置和外观。这使得 SHARP 能够重建一个可信的三维场景,而无需多张图像或缓慢的逐场景优化。SHARP 能够精确渲染附近的视角,而不是合成场景中完全不可见的部分。用户不能偏离拍摄照片的视角太远,因为该模型不会合成场景中完全不可见的部分。