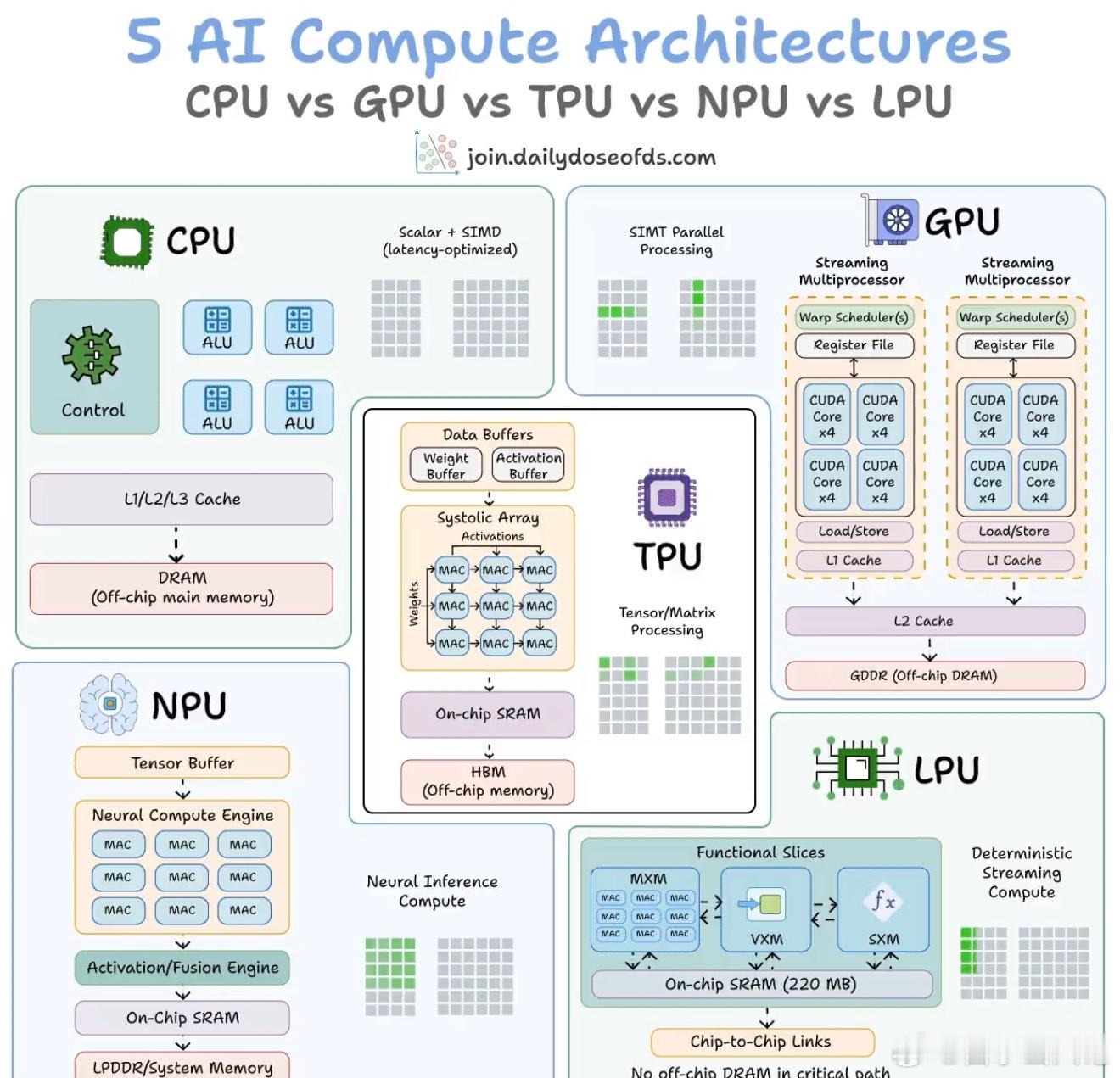
CPU vs GPU vs TPU vs NPU vs LPU,视觉化解释:
5 种硬件架构正在驱动当今的 AI。
每一种都在灵活性、并行性和内存访问之间做出了根本不同的权衡。
> CPU
它专为通用计算而构建。少数强大的核心处理复杂逻辑、分支和系统级任务。
它具有深层缓存层次结构和片外主内存(DRAM)。它非常适合操作系统、数据库和决策密集型代码,但不适合像矩阵乘法这样的重复数学运算。
> GPU
GPU 不是使用少数强大的核心,而是将工作分散到数千个较小的核心上,这些核心全部在不同的数据上执行相同的指令。
这就是为什么 GPU 主导 AI 训练的原因。这种并行性直接映射到神经网络所需的数学类型。
> TPU
它们在专业化方面更进一步。
核心计算单元是一个乘累加(MAC)单元网格,数据以波浪模式流动。
权重从一侧进入,激活从另一侧进入,部分结果传播时无需每次都返回内存。
整个执行过程由编译器控制,而不是硬件调度。谷歌专门为神经网络工作负载设计了 TPU。
> NPU
这是边缘优化的变体。
架构围绕神经计算引擎构建,该引擎装满了 MAC 阵列和片上 SRAM,但 NPU 使用低功耗系统内存,而不是高带宽内存(HBM)。
设计目标是在个位数瓦特功耗预算下运行推理,例如智能手机、可穿戴设备和物联网设备。
苹果神经引擎和英特尔的 NPU 遵循这种模式。
> LPU(语言处理单元)
这是由 Groq 推出的最新参与者。
架构完全移除了片外内存在关键路径上的存在。所有权重存储都位于片上 SRAM 中。
执行过程完全确定且由编译器调度,这意味着零缓存未命中和零运行时调度开销。
权衡在于,它每芯片提供的内存有限,这意味着需要数百个芯片链接在一起来服务单个大型模型。但延迟优势是真实的。
AI 计算已从通用灵活性(CPU)演变为极端专业化(LPU)。每一步都以某种程度的通用性换取效率。
下面的视觉图将所有五种的内部架构并排映射。
cpu微博股票gpu白山策略ChatGPTAI