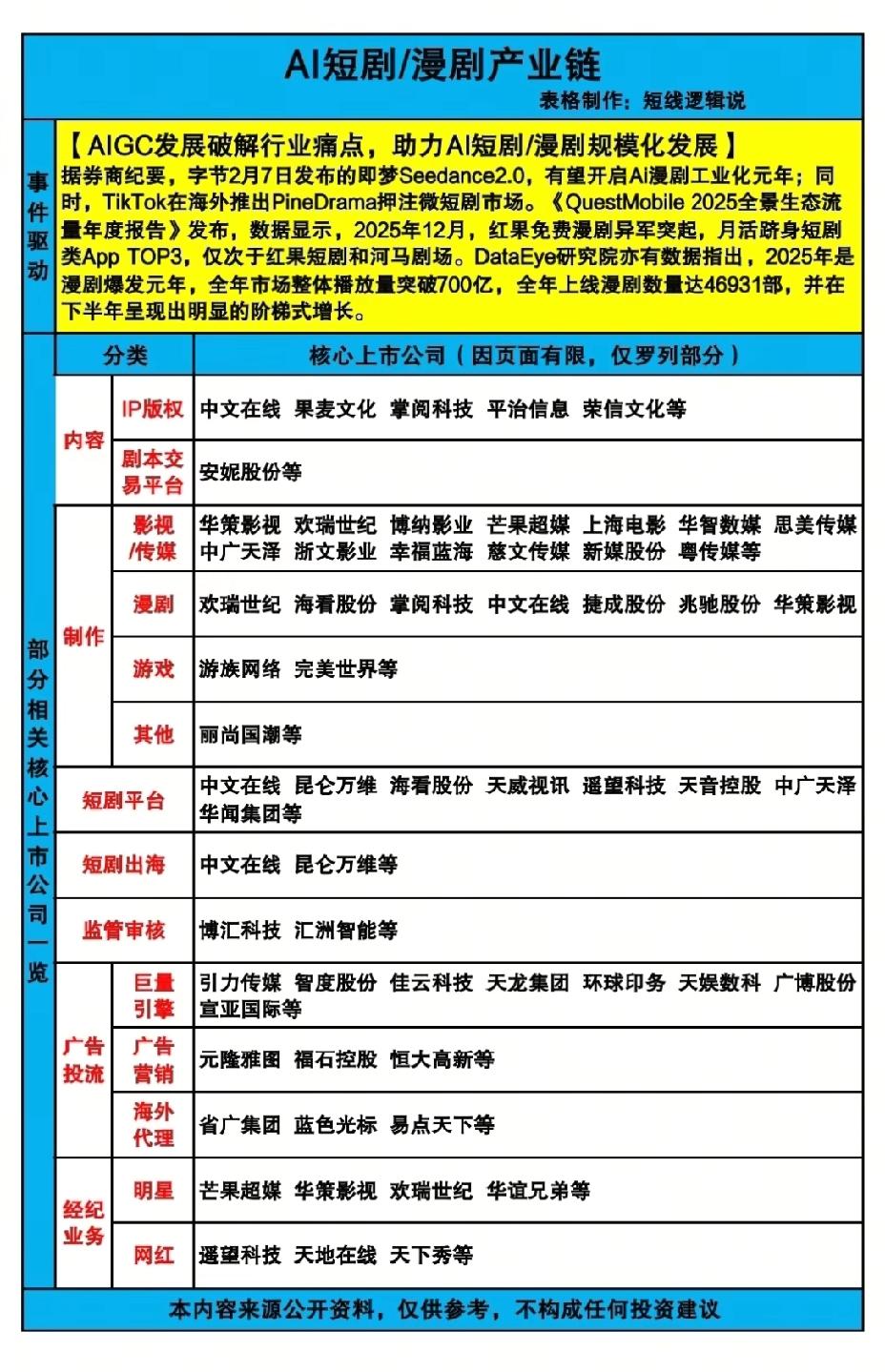
新加坡联合早报昨晚(2月9日晚)报道:“中国科技巨头字节跳动的Seedance2.0人工智能(AI)视频生成模型爆红,有网红博主担忧‘被训练’,让AI领域备受质疑的语料版权问题再次引发关注。” AI视频生成模型爆红背后的语料版权争议,核心症结根本绕不开数据获取的合规性难题。 Seedance2.0这类模型能快速生成高质量视频,本质是靠海量数据喂养出来的,而这些训练数据里,必然包含大量网红博主的原创视频内容。 这些内容不是无主之物,每一段都凝结着创作者的时间、精力和创意,从拍摄剪辑到内容构思,都是实打实的劳动成果,天然受版权法保护。 但现实情况是,很多AI模型训练时的语料收集,都存在“悄悄取用”的情况,既没有提前获得创作者授权,也没有给予相应报酬,这就是博主们担忧“被训练”的核心原因。 版权争议的第一个难点,在于法律界定的模糊地带。现行的版权规则大多是为传统创作模式制定的,面对AI这种新型技术,很多条款都显得滞后。 AI训练过程不是简单复制粘贴内容,而是通过算法提取作品的特征、风格和规律,再进行重组生成新内容。这种“学习式使用”到底算不算侵权,法律上还没有统一的明确标准。 有的观点认为只要不直接照搬原作品,就属于合理使用;但创作者这边,明明自己的创作风格被AI模仿,商业价值受到冲击,却很难找到确切的法律依据维权。 司法实践中也存在类似困惑,同样是AI使用他人作品训练,有的案件判侵权赔偿,有的却认定不构成实质侵权,这种不一致让版权边界变得更模糊。 举证难更是让创作者维权之路难上加难。AI训练是典型的“黑箱操作”,模型开发者不会公开具体的训练数据清单。 创作者要证明自己的作品被用于训练,得先拿出证据,可普通人根本无法获取AI的训练数据集,也没有技术能力去检测模型是否“学习”了自己的内容。 就算能证明模型生成的内容和自己的作品风格相似,也很难说服法院这是直接侵权导致的结果。毕竟AI可能学习了成千上万的同类作品,很难精准定位到某一个创作者的贡献。这种证据不对称的情况,让很多博主就算想维权,也只能望而却步。 行业发展的现实困境也加剧了版权争议。AI模型的竞争力,很大程度上取决于训练数据的规模和质量。 要想让Seedance2.0这样的视频模型生成效果逼真,就需要海量多样化的视频素材。 如果真的要逐一获得所有创作者的授权,不仅流程繁琐,还会产生巨额成本,对于AI公司来说几乎难以实现。这就形成了一个矛盾,一方面是AI技术需要大量数据才能发展,另一方面是这些数据的版权归属明确,不能随意使用。很多公司为了抢占技术先机,只能在数据获取上“打擦边球”,这也让语料版权问题一直悬而未决。 还有一个关键问题,就是权利分配的失衡。AI生成的内容能带来商业收益,这些收益大多归模型开发公司所有,但提供了核心训练素材的创作者,却得不到任何分成。 网红博主的视频内容,本身就是靠流量和商业合作变现,AI模型用他们的内容训练后,生成的相似视频可能会分流他们的流量,甚至抢占他们的商业机会。 这种“创作者付出劳动,公司享受收益”的模式,自然会引发强烈不满。而且目前没有任何机制能让创作者从AI使用中获得合理回报,这也让版权争议越来越突出。 语料版权问题不是第一次引发关注,之前AI绘画、智能写作等领域都出现过类似争议,但一直没有得到彻底解决。 Seedance2.0的爆红,只是再次把这个行业痛点摆到了公众面前。核心不是要否定AI技术的发展,而是要找到技术进步和版权保护的平衡点。 现在的问题是,法律规范、行业规则和技术手段都还没跟上AI发展的速度,导致版权争议不断出现。这种争议的背后,其实是创作者权益保护的诉求,也是AI行业健康发展的必然要求,只有把版权问题理顺了,AI技术才能走得更稳、更远。