[CL]《A Single Character can Make or Break Your LLM Evals》J Su, J Zhang, K Ullrich, L Bottou... [FAIR at Meta] (2025)
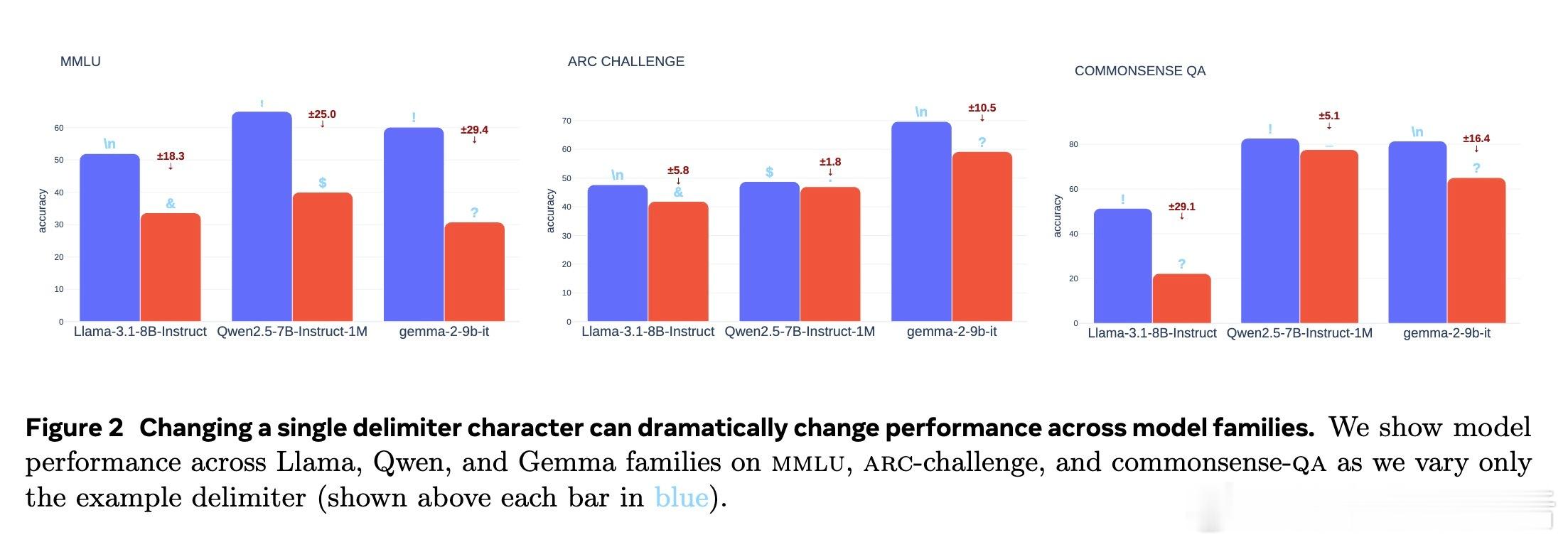
【一字符差异,LLM评测天壤之别】最新研究指出,分隔示例的单个字符选择竟能导致大型语言模型(LLM)评测成绩波动高达±23%!这不仅影响模型性能评估,还能轻易操控模型排行榜排名。
🔍 研究亮点:
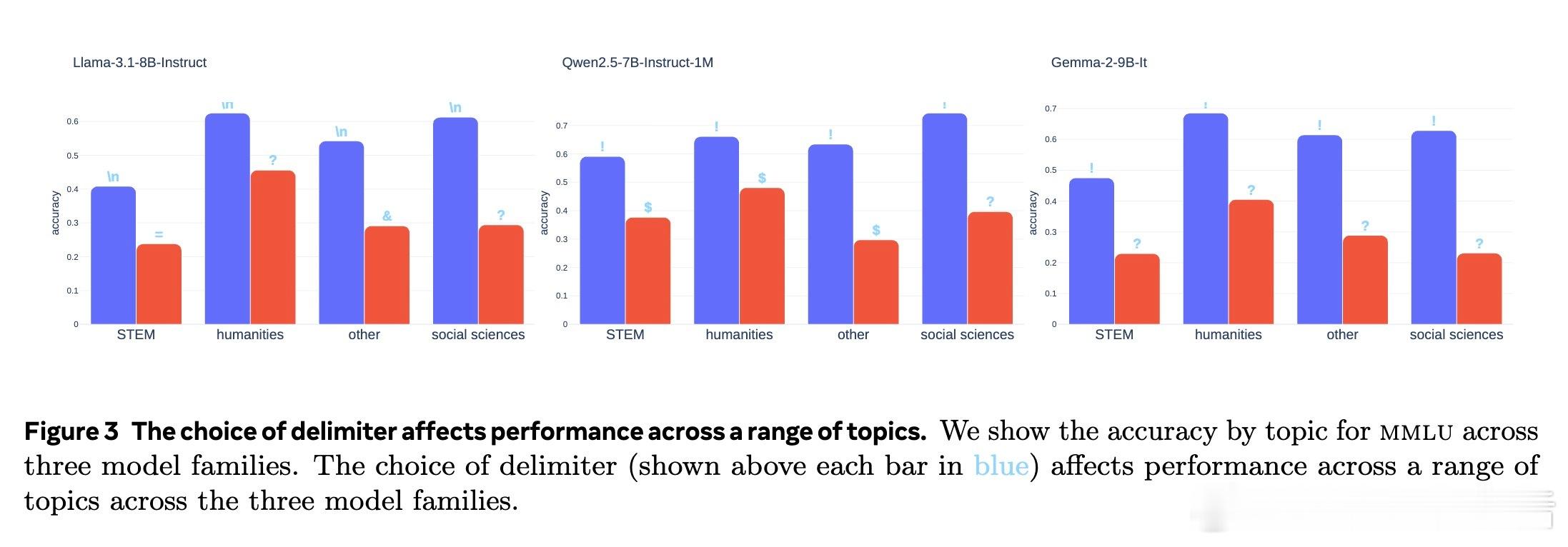
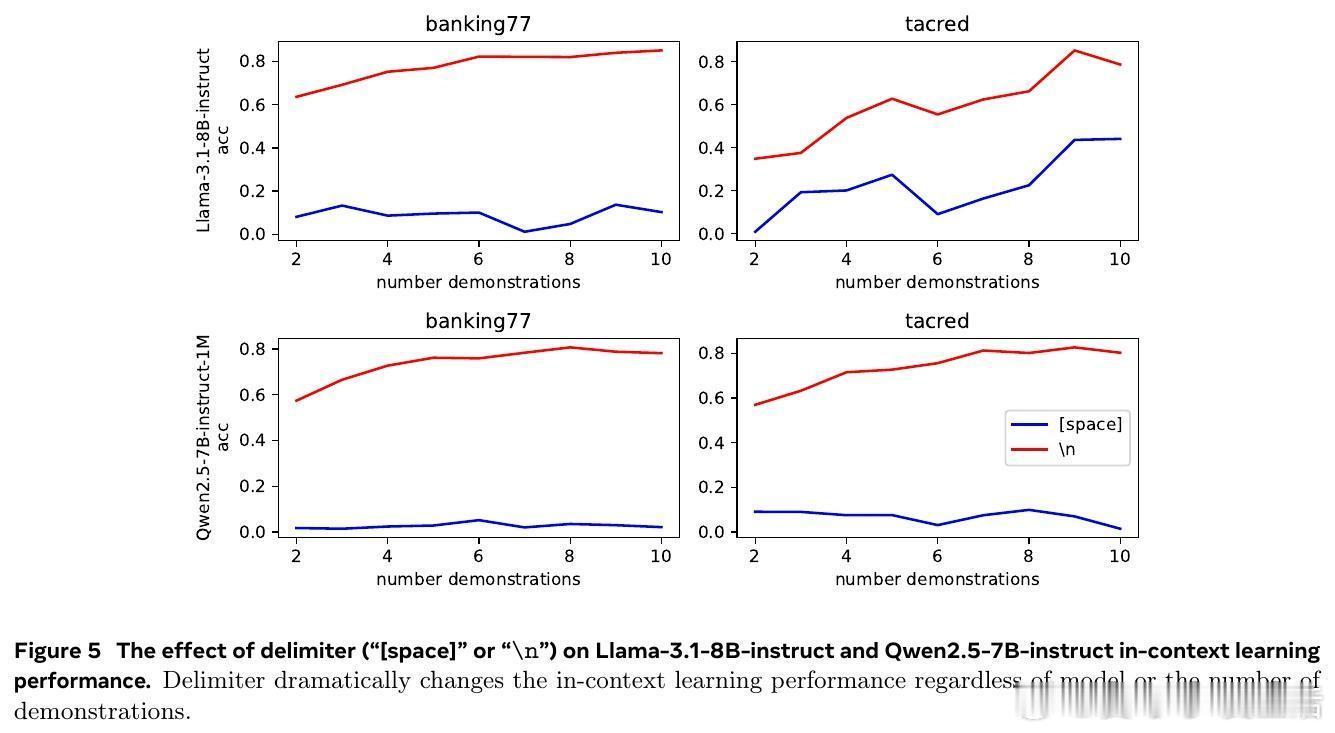
1️⃣ 评测中示例分隔符多样(逗号、换行、感叹号等),但不同分隔符对模型表现影响巨大,跨模型家族(Llama、Qwen、Gemma)和多任务均成立。
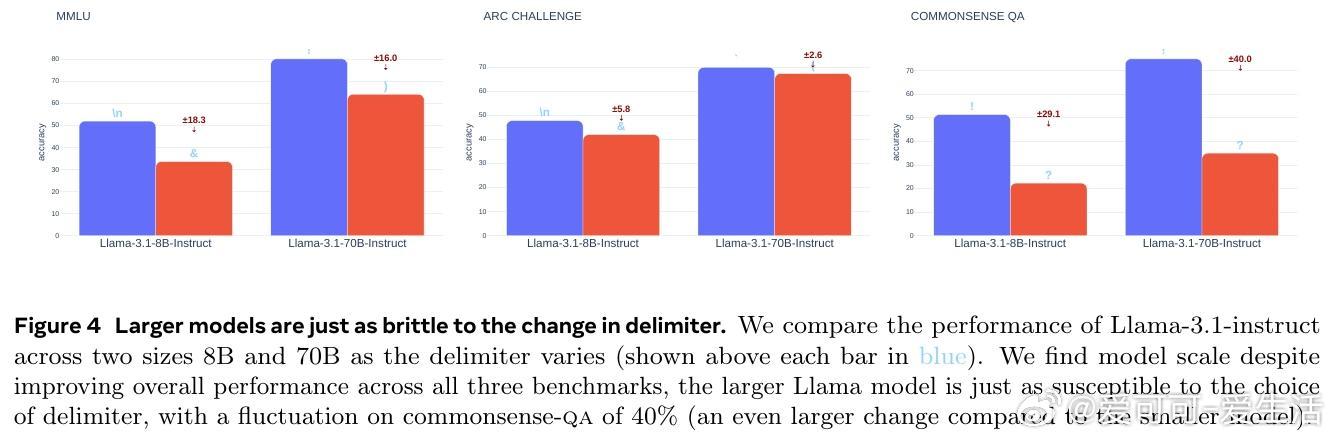
2️⃣ 模型规模提升(8B到70B)并未缓解分隔符敏感性,闭源模型如GPT-4o同样脆弱。
3️⃣ 通过分析注意力机制,发现优秀分隔符能引导模型聚焦关键输入,提升理解效果。
4️⃣ 简单地在提示中明确告知分隔符可显著增强模型鲁棒性,实测Qwen模型提升14.2%。
5️⃣ 实践推荐首选换行符“\n”和感叹号“!”作为分隔符。
💡 启示与建议:
- 评测和实际应用中,分隔符选择不可忽视,需标准化并明确告知模型。
- 模型开发者应关注格式敏感性,优化训练和推理流程以提升鲁棒性。
- 研究者需进一步探索格式与模型训练、架构交互机制,推动评测方法科学化。
完整论文详见:arxiv.org/abs/2510.05152
大模型 评测 提示工程 NLP 机器学习