[LG]《Understanding the Role of Training Data in Test-Time Scaling》A Javanmard, B Mirzasoleiman, V Mirrokni [University of Southern California & University of California Los Angeles] (2025)
深入理解训练数据在测试时扩展中的作用
推理时扩展(Test-time scaling)通过让大语言模型(LLMs)生成更长的思维链(Chain-of-Thoughts,CoTs),显著提升复杂推理能力。这使模型能分步解决难题、回溯纠错,性能显著增强。
但训练数据中哪些条件促成长CoTs出现?何时长CoTs真正提升表现?这些尚不清晰。
本文基于线性回归的上下文权重预测任务,理论解析测试时扩展的效果。核心发现:
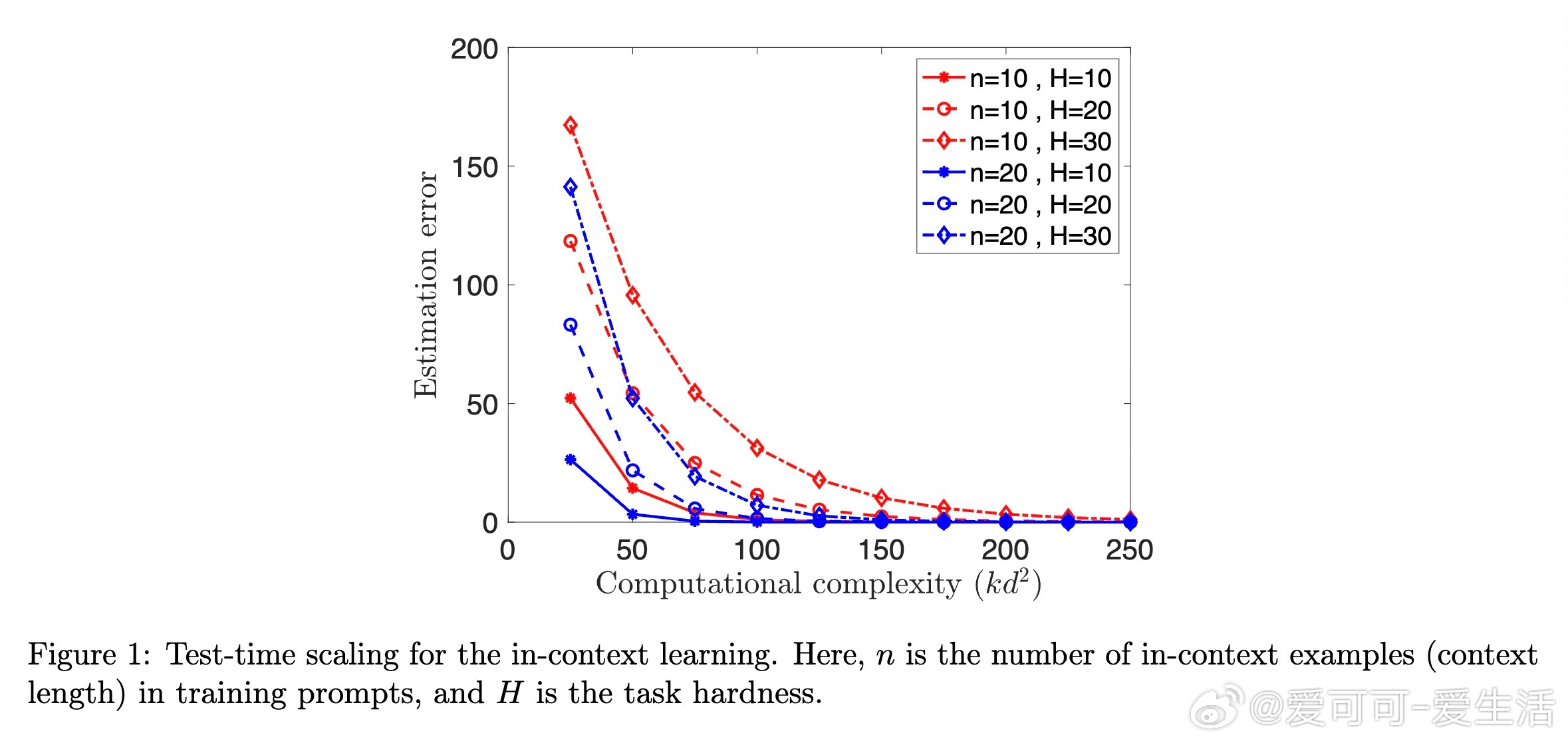
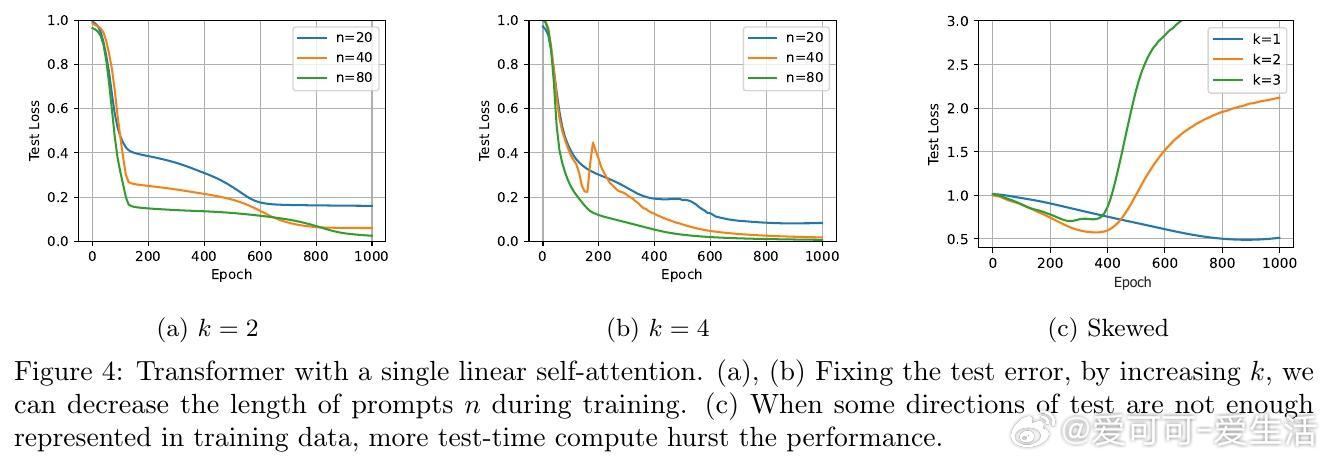
1️⃣ 在固定测试误差下,增加测试时计算量可减少训练时上下文示例的数量(即缩短训练prompt长度)。
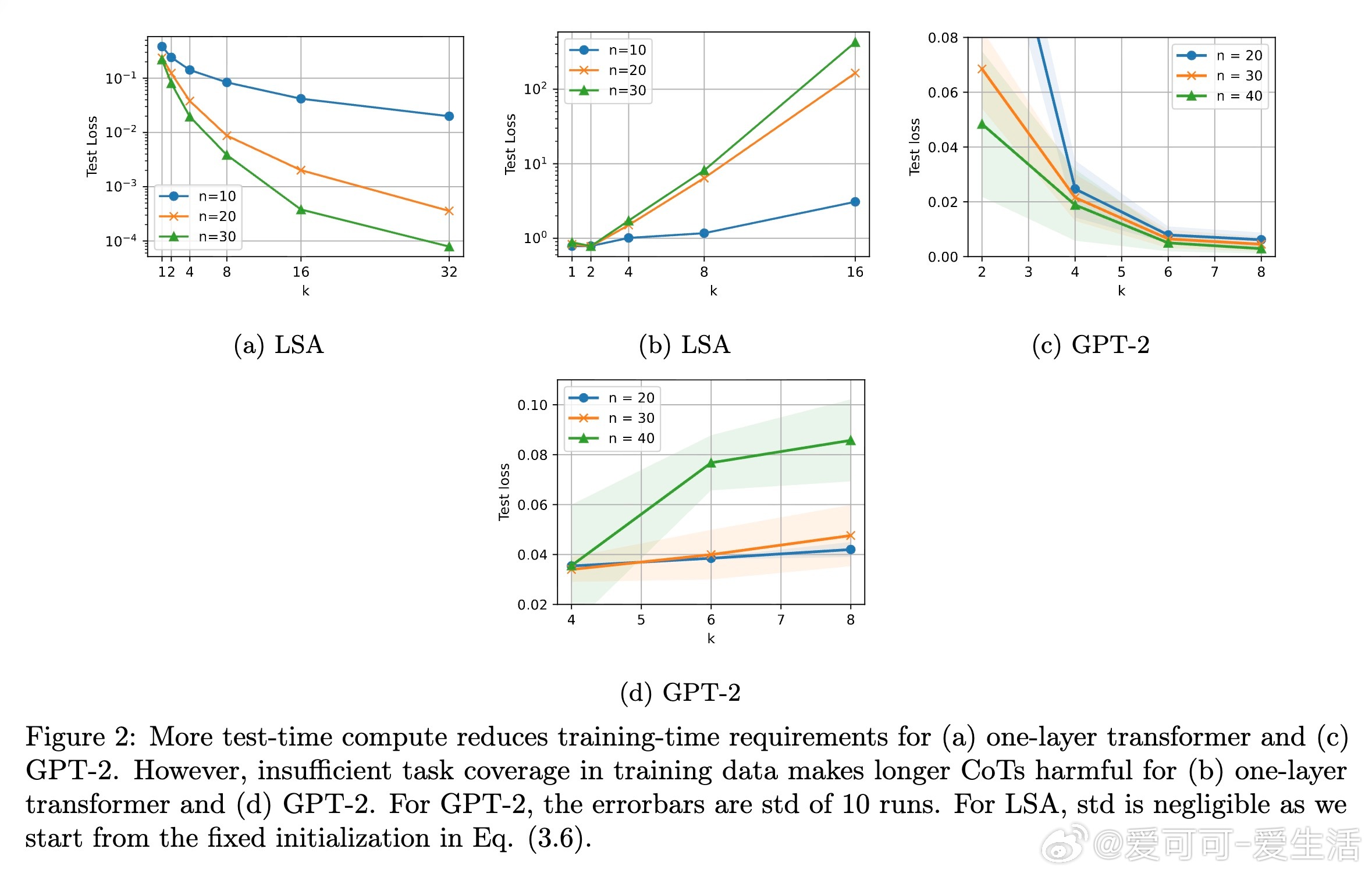
2️⃣ 若训练数据中缺乏解决下游任务所需的技能(对应数据协方差矩阵的方向),增加测试时计算量反而可能降低性能,导致“过度思考”现象。
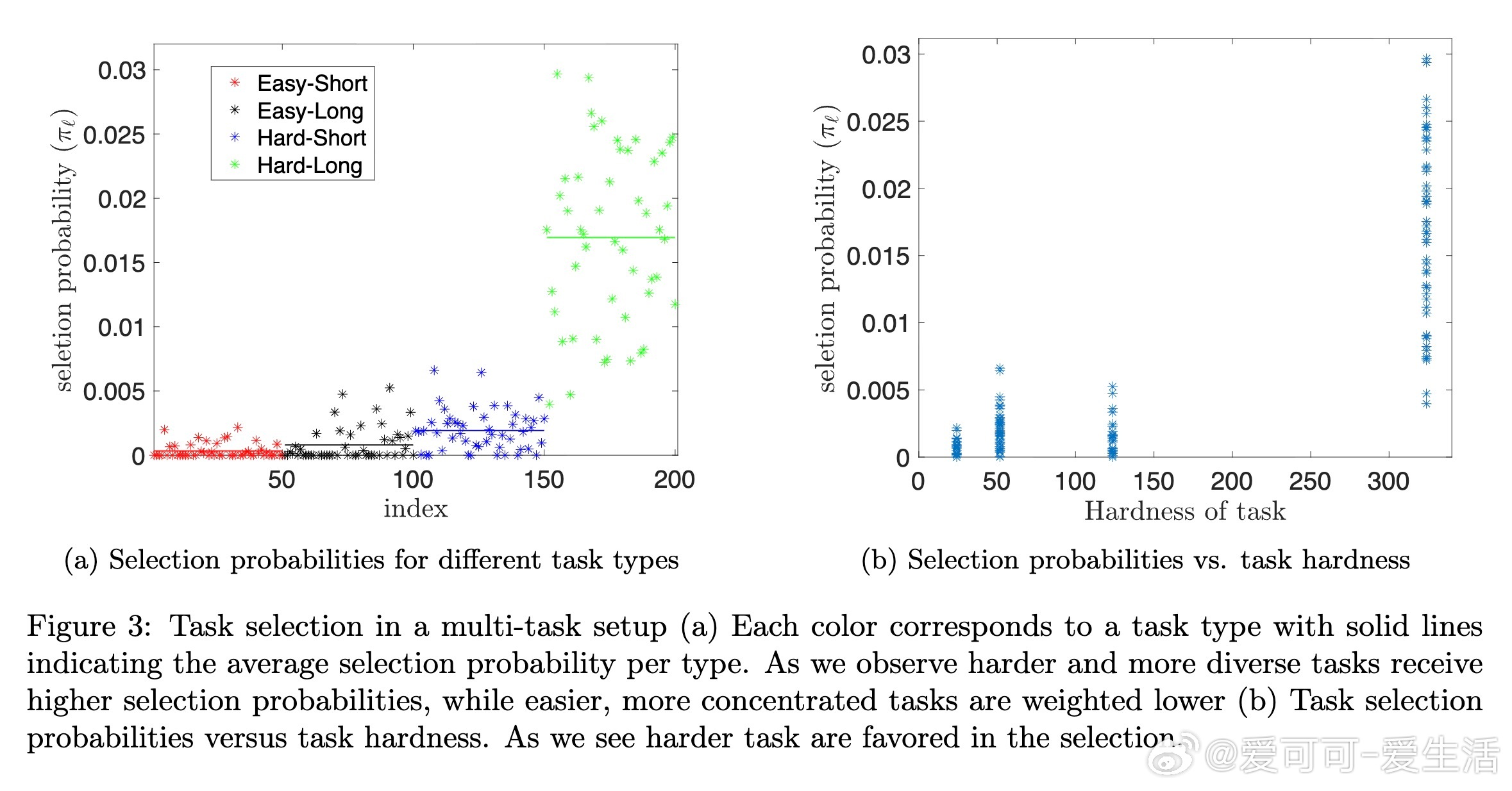
3️⃣ 通过特征协方差矩阵的最小特征值定义任务难度,训练时覆盖多样且难度适中的任务集合,能最大化测试时扩展效果。
理论上,测试时CoT推理相当于多步(伪)牛顿法优化过程,能动态调整预测。任务难度由技能分布的长尾特性刻画,难任务需更多思考步骤。多任务训练中,选择任务概率应优化覆盖目标任务的相关技能空间,且难度分布均衡。
实验证实:
✔️ 提升测试时思考步数,训练时上下文长度需求降低;
✔️ 训练数据若覆盖不充分,测试时多思考步数反而导致性能下降;
✔️ 训练任务选择倾向于多样、相关且困难的任务,提升泛化能力。
结语:本研究为理解和设计支持测试时扩展的训练数据提供理论基础,指导合理分配训练资源与选择任务,助力构建更强大、更高效的推理型大模型。未来工作将拓展到非线性模型和更复杂任务。
全文详见 arxiv.org/abs/2510.03605
大语言模型 测试时扩展 链式思维 任务选择 机器学习理论